Az adatbáziskezelés alapfogalmai
Információ és adat fogalmai A számítástechnika fejlődésének egyik fontos jellemzője, hogy egyre több felhasználó egyre több, számítógépen tárolt adatot használ fel. Az egyre növekvő információmennyiség egyre szélesebb körben válik elérhetővé. Az információ-hozzáférés így jelentkező demokratizálódásának hatása teljes joggal mérhető a könyvnyomtatás jelentőségéhez, ezért szokás ezt a jelenséget elektronikus Gutenberg forradalomnak is nevezni. Az elektronikus Gutenberg forradalom legfontosabb jellemzője, hogy - egyre nagyobb információmennyiség - egyre szélesebb tömegek számára - egyre demokratikusabban válik elérhetővé - a számítógép használatával. Az elkészített és alkalmazott számítógépi programrendszereknek növekvő adatmennyiséggel kell megbírkózniuk. A hétköznapjainkban is egyre gyakrabban találkozhatunk a számítógépes információs rendszerek alkalmazásával. Számítógépes információs rendszer fut az üzemekben, gyárakban a termelés irányítására, a pénzügyi, személyzeti, raktári, anyaggazdálkodási feladatok elvégzésére. Néhány hasonló alkalmazási terület az élet szinte minden területéről megemlíthető: - kereskedelem: raktári készlet és megrendelések nyilvántartása, - kultúra, oktatás: könyvtári információs rendszerek, hallgatói adminisztráció - közigazgatás: adónyilvántartások - közlekedés: jegyhelyfoglalási rendszerek - egészségügy: beteg nyilvántartás - tudomány: szakadatbázisok - posta: ügyfelek, számlák nyilvántartása - vállalat: termelés irányítási rendszerek - mérnöki munka: tervezői rendszerek. A példákat még hosszan lehetne sorolni. A felsorolásban gyakran találkozhattunk két, egymással igen rokonértelmű szóval e rendszerek jellemzésében, az információ és az adat fogalmaival. Az információt és adatot gyakran használják azonos értelemben, pedig e két fogalom között létezik jelentésbeli különbség, melyre oda kell figyelni, s célszerű tudatosítani magunkban e fogalmak pontos jelentését. Az információt jelsorozathoz kapcsolódó új jelentésnek, hasznos közlésnek tekinthetjük. Az információ fogalma alapfogalomnak tekinthető, értelmezésére is igen sokféle megközelítés létezik, melyek közül az egyik az általunk előbb megadott értelmezés. Az információ egyik fontos eleme az újdonság. Információ lehet pl. egy újsághír a minket érintő törvényváltozásokról. Nagyon sokféle módon, sokféle információhoz jutunk nap mind nap. Az információhoz szorosan kapcsolódik a - hordozó közeg, jel (hanghullám, fény,..) - jelentés és a - feldolgozó (pl. én magam, aki értelmezem a megkapott jelet) Az információ tehát mindig szubjektív fogalom, függ a feldolgozótól. Az információt igen sok oldalról lehet vizsgálni és elemezni. Az infdormációnak van - statisztikai - szintaktikai - szemantikai - pragmatikai oldalai. A szematikai oldal az információt hordozó jelek előfordulási gyakoriságait vizsgálja. E terület elméletének kidolgozása Shannon nevéhez kötődik. Statisztikai értelmében egy jelsorozat információtartalma a jelsorozat előfordulási valószínűségének reciprokával arányos. Erre egy szemléletes példa, hogy az nem hír, ha egy kutya megharapja a postást, de az már hírnek számít, ha egy postás harapja meg a kutyát. A szintaktikai oldal a jelsorozatok formális azonosságait vizsgálja, mely alapján a 'Jani szereti a sört' mondat hasonló felépítésű a 'Jani szereti Marit' mondattal. Az adatok viszont a feldolgozás során nyernek értelmet, s ekkor már a két mondat egészen más hatást válthat ki. Az adatok ezen rejtett tartalma a szemantikai oldal, mely a jelsorozat mögött húzódó jelentést, lényeget hangsúlyozza. A pragmatika a jelentés gyakorlati hasznosságát emeli ki. Egy elméletileg hasznos információ nem alkalmazható, ha felhasználásához nagyon hosszú idő szükséges, vagy ha az elérhető haszon elhanyagolhatóan kicsi. Majd a későbbi modellezési fázisokban közvetlenebbül is tapasztalhatjuk a különböző oldalak fontosságát. Az információ fontosságát, lényegét mutatja, hogy az információ is a világegyetem alapfogalmai közé tartozik, hasonlóan az energia, anyag fogalmaihoz. E fogalmak egyenrangúságát mutatja a Maxwell démon gondolatkisérlete. Ebben szerepel egy súlyzó alakú gáztartály, melynek közepén van egy kis kapu, melyen át a gázmolekulák a két féltér között vándorolhatnak. A gázmolekulák dinamikus egyensúlyban vannak a két féltér között, egyenlő a nyomás a két oldalon. Ha egy kis démont képzelünk el a kapunál, mely nem engedi át a gyors részecskéket baloldalról a jobboldalra, és nem engedi át a lassú részecskéket a jobboldalról a baloldalra, az ablak mozgatásával, akkor a baloldal felmelegszik, a jobboldal lehűl. Ezáltal megnő a rendszer összenergiája. Az energianövekedést a démon a gázmolekulákra vonatkozó információ birtokában érhette el, az információ rovására. Tehát az információ átalakult energiává, ami az energia és az információ ekvivalenciáját szemlélteti. Az információknak a társadalomban betöltött szerepét mutatja, hogy az energia pénzt, hatalmat is jelent. A kellő időben megszerzett információ felhasználható előny szerzésére. Az információ elvesztése pedig ennek megfelelően hatalmas károkat okozhat. Az információ, mind szubjektív fogalom, szorosan kötődik hordozó közegéhez, mely már objektív jelenségnek tekinthető. Az információ hordozóját adatnak nevezzük, vagyis az adat a tények, fogalmak, feldolgozásra alkalmas reprezentációja. Az adat objektív, feldolgozótól független. A témánkból eredően, mi az adat fogalmát egy kicsit szűkebben, a számítógépen tárolt adatokra értelmezzük. Az adat számunkra a számítógépben tárolt jelsorozatot jelenti, melyből a feldolgozás során nyerhetünk információt. Az adat a számítógépben viszont még információ nélküli jelsorozatként tárolódik. Az információ feldolgozására készített számítógépes programok az adatokat különböző strukturáltságban kerülnek letárolásra. Az adatok lehetnek egy lazább szerkezetben, és egy szigorúbb, finomabb struktúrában letárolva. Ennek megfelelően beszélhetünk: - szövegszerű rendszerekről - adatszerű, finoman struktúrált rendszerekről. A szövegszerű tárolásnál a dokumentumok, könyvek, cikkek alkotják a legkissebb elérési egységet, s a dokumentum belső struktúra nélkül, ömlesztve tartalmazza az információt. Az adatszerű tárolásnál sokkal kisebb adatelemek, egyedek tulajdonságai is elérhetők és kezelhetők. Ekkor rákérdezhetünk pl. egy ember nevére, lakcímére, azaz minden egyedi tulajdonságára is. A feldolgozandó témáink az adatszerű, strukturált adattároláshoz fognak csatlakozni. Az információs rendszerek követelményei A bevezetőben is említett információs rendszerek egyik fontos jellemzője, hogy nagy adathalmazt kezelnek, s az adatok között is bonyolultabb kapcsolatok állhatnak fenn, s ezen adatokat, kapcsolatokat hosszabb időszakon át is meg kell őrizni. Ma már több tucat olyan információs rendszer létezik a világon, amlyek több terrabyte nagyságrendű adatot tartalmaz. Természtesen az információs rendszerek döntő többsége ettől jóval kisebb méretű. A Gartner Group elemzése alapján 1997-ben a 200-400 Gbyte-tól nagyobb méretű adatrendszereket tekintik nagyon nagy adatrendszereknek. E rendszereket a VLDB (Very Large Data Bases) rövidítéssel is szokták jelölni. A nagy és bonyolult adatrendszer mellett egy sor más egyedi sajátossággal, követelmény rendszerrel lrendelkeznek ezen információs rendszerek, melyeket a rendszer fejlesztői kénytelenek számításba venni, hogy jól működő, az igényeket kielégítő termékkel álljanak elő. A következőkben összefoglaljuk mindazon követelményeket, melyeket egy, a vállalat működése szempontjából fontos információs rendszernek feltétlenül teljesítenie kell. - Nagymennyiségű adatok hatékony kezelése. A felhasználónak elfogadható időn belül kell választ kapnia a feltett kérdéseire, a kiadott utasításoknak sem szabad szokatlanul sokáig tartaniuk. A hatékonyság tehát egyrészt jelent egyfajta időbeli hatékonyságot, másrészt az adatok helyszükségleteinek sem szabad feleslegesen megnőni, úgymond kerülni kell a felesleges redundanciát, azaz egyazon adatelem többszöri, felesleges megismétlését. Mind majd később látható a redundancia teljes megszűnése nem mindig kívánatos, más a helytakarékossággal szemben álló egyéb szempontok miatt, pl. a éppen az időbeli hatékonyság, vagy az adatbiztonság miatt. A fejlesztőnek meg kell találnia a hatékonyság különböző szempontjainak helyes súlyozását, optimalizálnia kell, hiszen ezek a szempontok gyakran egymással ellentétes lépéseket követelnek. - Konkurens hozzáférés támogatása. A nyilvántartó és információs rendszerek rendszerint nem személyi rendszerek, nem PC-n futnak. Természetes használati módjuk, hogy egyidejűleg több felhasználó is használja, dolgozik vele. Ez a lehetőség viszont különös elővigyázatosságot igényel, hiszen a párhuzamos változtatások, műveletek, ha nincsenek összehangolva, akkor torz eredményeket szülhetnek, egymás hatásait kiolthatják vagy elferdíthetik. Ennek egyik szemléletes példája, az ún. lost update jelensége, vagyis amikor az egyik alkalmazásban végrehajtott adatérték-módosítás hatását törli egy másik alkalmazásban elvégzett módosítás (1. ábra). Ekkor úgymond elveszik az első módosítás. Ez igen kényes hatással is járhat, ha mindez mondjuk egy bérügyi nyilvántartó rendszerben zajlik le, s az első alkalmazás a rendkívüli fizetésemelést, a másik meg a rendszeres fizetésemelést végzi el. Senki sem örülne az elveszett fizetésemelésnek. Az osztott erőforráshasználat problémája egyébként nemcsak itt keletkezik, hasonló nehézséggel találkozhattunk az operációs rendszerek területén is. Megoldásához nyilván kell tartani az elvégzett műveleteket, s gondoskodni kell a műveletek szabályozott sorrendben történő végrehajtásáról is.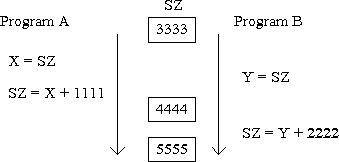
Ábra 1. - Integritásőrzés. A modellezett, programba leképezett valóság mindig rendelkezik belső törvényszerűségekkel, egy ilyen szabály lehet pl. hogy minden embernek van születési ideje, vagy pl. az ember életkora nem lehet negatív. A letárolt adatok helyessége, integritása alatt azt értjük, hogy az adatok minden megadott belső szabálynak megfelelnek. Az előbbi példát véve ismét, nem fordulhat elő, hogy egy életkor -13 év legyen. Természetesen a szabályok a példánál megadottaknál sokkal bonyolultabbak is lehetnek, amikor adatok közötti kapcsolatokat is vizsgálni kell. Erre vehetjük példaként, hogy egy kereskedő csak akkor szállít, ha a kért áruból legalább egy x mennyiség a raktáron marad és a rendelő minden előző számláját már kiegyenlítette. Az integritás megőrzéséhez a rendszernek először is nyilván kell tartania a szabályokat valamilyen hatékonyan kezelhető formában, majd minden művelet alkalmával ellenőriznie kell, hogy a kapott adathalmaz megfelel-e a letárolt szabályoknak. Mindezt olyan hatékonysággal, hogy a végrehajtási idő még az elviselhetőség határán belül maradjon. - Védelem. A számítógépes információs vagy irányítási rendszereket a felhasználó a manuális tevékenységek kiváltására használja, hiszen ha mindent duplázva, kézzel és számítógéppel is végig kell vinni, akkor a munka hatékonysága nemhogy növekedne inkább csökken. Ez azt is jelenti, hogy a felhasználó rábízza magát, azaz összes adatát a számítógépes rendszerre vagyis a legtöbb adat csak ott tárolódik. A tárolt adatok elvesztése szinte pótolhatatlan veszteséget okozhatnak. Ezért a rendszernek fel kell készülnie, amennyire csak lehet a veszélyekre, mint az adathordozó megsérülése, az operációs rendszer vagy a program összeomlására. Az adatvesztés elkerülésének fontosságát, az elveszett adatok visszaszerzésére irányuló igényt jól mutatja a Kürt cég sikertörténete is, mely sérült adathordozók helyreállítására specializálódott. Az adatsérülés mellett a felhasználóra leselkedő másik veszélytipus, az adatok illetéktelen személyekhez történő kerülése. Bizonyára akadnak olyanok, akik nagyon kíváncsiak lennének egy gyár termelési adtaira, a technológiára, vagy éppen mások adataira, esetleg egy légvédelmi rendszer részleteire. A rendszernek tehát, ismét hasonlóan az operációs rendszerekhez, szabályoznia és ellenőriznie kell a hozzáféréseket, különbséget kell tennie az egyes felhasználók között a elvégezhető műveletek tekintetében. Ehhez a viszont nyilván kell tartani a jogosult felhasználókat, azok jogait és minden műveleti igény kiadásakor ellenőrizni kell, hogy elvégezhető-e a művelet. Ennek egyik ismert megoldása a hozzáférés monitoring rendszer, mely ellenőrzi és naplózza is az erőforrás-hozzáféréseket. A hozzáférési védelem egyik másik elterjedt módszere a titkosítás. A kódolandó adatokat áttranszformálják kódolt adatokra, ahol a kódolás folyamata rendszerint egy vagy több paramétertől is függ, ezeket szokás a kódolás kulcsainak is nevezni. - Hatékony programfejlesztés A rendszer kifejlesztési idejének lerövidítésére több oldalról is jelentkező nyomás hat. Egyrészt a szoftverpiacon folyó versenyben a rövidebb határidő előnyhöz juttathatja a versengőket, hiszen a felhasználó minél előbb szeretné kihasználni a rendszer által nyújtott előnyöket. Másrészről a gyorsaság bizonyos értelemben alapkövetelmény is, hiszen a rendszer mindig a valóság egy modelljének felel meg, s a modellezett valóság elég gyakran változik, pl. megváltoznak a szabályozók, a törvények. Egyik felhasználó sem kíván olyan rendszert megrendelni, mely használhatatlan lesz mire elkészül. A modellezett valóság változásai azonban előbb vagy utóbb mindenképpen kisebb vagy nagyobb mértékben bekövetkeznek. Viszont ezek a rendszerek már elég drágák ahhoz hogy minden kisebb változtatás után a felhasználó egy újabb rendszert rendeljen meg. A rendszernek tehát elég rugalmasnak kell lennie a kisebb változtatások elvégzésére. A rugalmasság és a gyorsaság igényei hatékony fejlesztő eszközök használatát teszik szükségessé a programfejlesztés során. A futtató környezetek sokfélesége felveti a szabványosság kérdését is. A szabványos eszközök használata ugyanis megkönnyíti az alkalmazások új platformra történő átültetését, és a fejlesztők egymás közötti kommunikációját, a fejlesztő rendszer elsajátítását is hatékonyabbá teszi. Az előzőekben felsorolt szempontok és problémák tükrében talán már érzékelhető, hogy nem kis feladat pl. egy jó nyilvántartó rendszert kifejleszteni. Ha a rendszer adatkezelő részét emeljük csak ki, akkor is hatalmas munka lenne az igényeket kielégítő alkalmazás kifejlesztése az eddigiekben megismert programfejlesztő rendszerekkel, mint pl. a C programozási nyelvvel. Vegyük egy kicsit részletesebben, miként is járhatnánk el az adatrendszer C nyelvvel történő kifejlesztésénél, ezzel egy rövid áttekintést adva az adatkezelés legfontosabb alapfogalmairól is. Áttekintés az adattárolás struktúrájáról Az alapvető tárolási mechanizmusok áttekintése során számos olyan fogalmat frissítünk fel, melyekre a későbbiekben, az adatbázisok tárgyalása során is szükség lesz. A felelevenítés mellett e áttekintés arra is rá kíván viágítani, hogy milyen összetett és aprólékos feladat az adatok hatékony tárolási mechanizmusának megvalósítása. Az adatkezelő rendszereknél a permanens adatok állnak az adatkezelés központjában, tehát azok az adatok, melyekre hosszú ideig, az alkalmazásból történő kilépés után is szükség van. A permanens adatok tárolására a háttértárolók szolgálnak, ahol az adatok file-okba szervezetten helyezkednek el. A nagy adatmennyiségből eredően minden pillanatban az adatoknak csak egy töredéke fér el fizikailag a központi memóriában. Ha a file-on belüli tárolás kérdését vizsgáljuk, akkor meg kell ismerni a lehetséges fileszervezési módszereket és azok hatékonyságait az olyan alapvető műveleteknél, mint az - adatelemek megkeresése, lekérdezése - adatelemek bővítése, módosítása, törlése - segédinformációk tárolása. A leggyakoribb művelet a felsoroltak közül a lekérdezés. Természetesen lehetnek olyan alkalmazások, ahol ez nem teljesül, mert pl. csak archiválni kell, és csak nagy ritkán van szükség visszakeresésre. Nézzük tehát milyen fizikai tárolási struktúrát válasszuk, ha a hatékony lekérdezésre koncentrálunk. A hatékonyságnövelési lehetőségek keresését valójában már az adathordozó szintjén el kell kezdeni, hiszen mágneslemezt véve, mint leggyakoribb adathordozót, az adatelem beolvasása a címének ismeretében három fő lépésből áll, melyek különböző időszükséglet rendelhető: - fejmozgatás: a fejet a lemez megfelelő sávjára, cilinderére kell mozgatni. - fejkiválasztás: lemezcsomag esetén a megfelelő lemez kijelölése - forgatás: az adott sávon belül a megfelelő szektor, blokk mozgatása a fej alá. Ebből a három elemből a fejmozgatás igényli a legtöbb időt, átlagosan a teljes idő mintegy 80 százalékát. A fejmozgatáshoz szükséges idő azonban lényegesen függ attól, hogy hol helyezkedik a sáv, mi volt az előzőleg felkeresett sáv. Minden sávváltás időszükséglettel jár, mégpedig minél nagyobb volt a távolság, annál több idő szükséges. Ebből két számunkra fontos megállapítás is levonható: - az egymásután, együtt olvasott adatokat célszerű ugyanazon vagy szomszédos sávokra elhelyezni - egy adatelemnek, más programok véletlenszerű sávpozícióit feltételezve, az optimális elhelyezkedése a középső sávokban található. Ha van befolyásunk az adatelemek elhelyezésére, akkor a fentiek figyelembe vételével kell dönteni. A következő lépcsőfok a megfelelő fileszervezés kiválasztása. A fileokon belül az adatok blokkokban tárolódnak, ahol egy blokk egy adatátviteli egységnek fogható fel, azaz egy írás vagy olvasás művelete minimum egy blokk adatmennyiséget mozgat az adathordozó és a központi egység között. A filehoz tartozó és egymás után következő blokkok nyilvántartására is több különböző módszer létezik: - blokkok láncolása, azaz minden blokkban van egy mutató a következő blokkra. Az első blokk címének ismeretében sorban felkereshető az összes többi blokk. - blokk címlista, azaz minden filehoz létezik egy lista, amely a hozzá tartozó blokkok címeit tartalmazza. Ez a lista lehet egyszerű, összefüggő, de lehet bonyolultabb felépítésű is. A blokkok a file-ok fizikai szerkezetét mutatják, de emellett a file egy belső logikai struktúrával is rendelkezik. A logikai fileszerkezet alapvetően lehet - stream jellegű vagy - rekord jellegű. A stream filetipusnál a file egy belső struktúra nélküli byte vagy karakter sorozatból áll. A karaktersorozatot a felhasználó programm értelmezi saját igénye szerint. Ugyanazt a filet a különböző programok másképp értelmezhetik. A rekord jellegű szerkezetnél feltesszük, hogy a file felbontható logikai részelemekre, úgynevezett rekordokra. A rekord egy logikailag összetartozó adatelemek, mezők összessége. Egy rekord jelentheti pl. egy alkalmazott összes adatát, és egy mező egy adatelem, mint pl. a név, beosztás vagy a fizetés. A rekord és a blokk viszonya alapján beszélhetünk - spanned rekordokról, amikor egy rekord több blokkra is kiterjedhet, és - unspanned rekordokról, amikor egy rekord csak egy blokkhoz tartozhat. A rekord jellegű állományokban a rekordok lehetnek - fix hosszúak, vagy - változó hosszúságú. Változó hosszúságú rekordok esetén a rekordok elhelyezkedését jelezheti - rekordvég karakter - mutató a következő rekord elejére - blokklista a rekordokra hivatkozó mutatókkal Ha az adatelemek gyors elérését kívánjuk elérni, akkor a belső struktúra nélküli stream filekezelés nem megfelelő, hiszen ebben az esetben csak a file soros átolvasásával találhatjuk meg a keresett elemet, ami azt is jelenti, hogy átlagosan a file felét át kell olvasni egy elem megtalálásához. A rekordjelllegű megközelítés esetében is megvalósítható ez a számunkra nem előnyös felépítés, ugyanis a rekordjellegű file szerkezeteknek az alábbi típusai ismertek: - soros elérés - szekvenciális elérés - indexelt elérés - random, hashing elérés. Az egyes elérési, szervezési módok közötti különbség megértéséhez szükség van egy újabb fogalom a rekordkulcs megismerésére. A rekord mint már említettük, egy egyed több tulajdonságát tartalmazhatja. Ezen tulajdonságok között vannak olyanok, melyek több egyednél is ugyanazt azt értéket vehetik fel. Az dolgozók adatait leíró rekordban például a születési hely, vagy a fizetés több dolgozónál, azaz több rekordban is lehet ugyanaz az érték. Vannak azonban olyan mezők, azaz az egyed olyan tulajdonságai, melyeknek egyedieknek kell lenniük. Ilyen tulajdonság lehet pl. a dolgozó törzsszáma, személyi száma. Az ilyen tulajdonságot, vagy tulajdonságcsoportot, mely egyedisége révén alkalmas az egyed, azaz a rekord egyértelmű azonosítására, rekordkulcsnak vagy röviden kulcsnak nevezzük. Az adatelemek keresésénél kiemelt fontosságúak lesznek azok az esetek, amikor a keresés a kulcsra vonatkozik, mivel ez a rekordok egy természetes keresési módját jelenti. Tehát nem a pozícó alapján keresünk, mint ahogy az a tömbök esetében megszokott volt. Ez alapján az egyes fileszervezési módok az alábbiakban foglalhatók össze: - Soros elérés. A rekordok a fileban tetszőleges sorrendben, pl. a felvitel sorrendjében helyezkednek el, azaz nincs kapcsolat a rekord kulcsértéke és a rekord file-on belüli pozíciója között. Mivel ekkor egy adott kulcsértékű rekord bárhol elhelyezkedhet a fileban, a kereséskor a file minden rekordját át kell nézni egymásután a file elejétől kezdve, amíg meg nem találjuk a keresett rekordot. Ez átlagosan a file-ban tárolt rekordok felének átnézését igényli, ezért az egyedi keresések szempontjából nem tekinthető hatékony módszernek. Természetesen ha minden filehozzáférésnél szükség van összes rekordra, akkor ez a fileszervezés lesz a leghatékonyabb. - Szekvenciális elérés A rekordok a fileban a kulcsértékeik alapján sorba rendezve helyezkednek el, pontosabban a rekordok a fileban a kulcsértékeik növekvő vagy csökkenő sorrendjében érhetők el. A szekvencia előnye, hogy nem szükséges a teljes file-t végignézni adott kulcsértékű rekord keresésekor, mivel a sorrendbe rendezés miatt egy adott kulcstól jobbra csak tőle nagyobb (növekvő rendezést feltételezve) kulcsértékű elemek helyezkedhetnek el. Ez a sorrendbe rendezés megvalósítható fizikai szekvenciával vagy logikai, láncolt szekvenciával. A fizikai szekvenciánál a rekordok fizikai helye megfelel a sorrendben elfoglalt helyének. Ezáltal gyors lesz az egymást követő rekordok elérése, de egy új rekord beszúrása esetén át kell rendezni a rekordokat a file-on belül, egyes rekordokat át kellvinni más blokkokba, hogy helyet biztosítsunk a beszúrandó rekordnak. Gyakran változó file esetén tehát nem javasolt ez a módszer. A logikai szekvencia esetén a rekordok a bevitelük sorrendjében helyezkednek el fizikailag a fileban, s a sorrendbe rendezettséget mutatók segítségével valósítják meg, azaz minden rekord tartalmaz egy mutatót a sorrendben őt követő rekordra. Így beszúráskor csak a mutatókat kell átrendezni, a rekordok fizikai pozíciója ugyanaz marad. Mivel mind a két esetben továbbra is a file elejéről kiindulva, az egymást követő elemek ellenőrzésével lehet keresni, ez a módszer sem igazán hatékony számunkra. - Indexelt struktúra. A keresés meggyorsítható lenne, ha nem kellene minden, a keresett rekordot megelőző rekordot fizikailag is átolvasni. Valójában a keresett rekordot megelőző rekordokból csak azok kulcsértékei fontosak számunkra, a rekord többi mezője lényegtelen. Mivel rendszerint a kulcsmező nagysága csak egy töredéke a teljes rekord méretének, ezért ezen redukált adatokat sokkal gyorsabban át lehetne olvasni, sőt egy minőségi javulást hozna, ha az átolvasandó sor elhelyezhető lenne a memóriában, ugyanis ekkor az egymásutáni elembeolvasások helyett egy sokkal gyorsabb keresési módszer, a bináris keresés is alkalmazható lenne. Mindennek megvalósítása az index szerkezet, mely egy külön listában tartalmazza a rekordok kulcsait és az elérésükhöz szükséges mutatókat. A legegyszerűbb indexszerkezet egy indexlista, mely az összes rekord kulcsát tartalmazza egy listában, ahol a kulcsértékek rendezetten helyezkednek el. Mivel nagy fileméreteknél az indexlista is olyan hosszú lehet, hogy már nem fér egyszerre a memóriába, a lista kezelhetővé tételére új megoldásokat kerestek. Ennek egyik módszere az indexszekvenciális fileszerkezet, az ISAM szerkezet, melyben a rekordok fizikailag is rendezetten helyezkednek el a fileban, mint a szekvenciális állományoknál, így az indexlistának nem szükséges minden elemet tartalmaznia, csak bizonyos jelző rekordokat, mondjuk minden k.-kat, s rekord keresését a file-ban a hozzá legközelebb eső, tőle kisebb kulcsértékű jelzőrekordtól kell csak kezdeni. Az állományban történő szekvenciális keresés sem tarthat sokáig, hiszen maximum k rekordot kell egymásután átnézni. Az ISAM fejlettebb módozatainál külön van cilinder (sáv) és blokk index, mely a fejmozgás csökkentése érdekében ugyanazon cilinderen helyezkedik el mint a blokk, a rekord. Ez a megoldás igazán akkor hatékony, ha a cilinder index a központi memóriában helyezkedhet el. A másik lehetséges, elterjedt módszer a többszintű, hierarchikus indexstruktúra bevezetése, melyben a felül elhelyezkedő listából nem közvetlenül a rekordokra, hanem újabb indexlistákra történik hivatkozás. A hierarchikus index listák között kiemelkedő szerepet játszik a B+ fa (2. ábra). A B+ fa előnye, hogy minden, közvetlenül a rekordokra mutató listája a fa (a levél listák) , a hierarchia azonos szintjén helyezkedik el. Ez azt is jelenti, hogy minden rekordot közel azonos idő alatt érhetünk el, azaz az indexszerkezet kiegyensúlyozottnak mondható. Az indexlisták kihasználtsága is jónak mondható, hiszen minden lista, az elsőt kivéve, kapacitásának legalább a felét kihasználja. A keresés elve megfelel a keresőfák megszokott algoritmusának. A fa új elemek beszúrásakor sajátosan, lentről felfelé bővül. Előbb megkeresik azt a levél listát, ahol lenni kellene a bejegyzésnek. Ha van még itt hely, beszúrják ide a bejegyzést a sorrend szerinti helyre. Ha nincs hely, akkor megkeresik a helyét, majd a középső elemet kiemelik ebből a levélből, feltolják a szülő listába, majd létrehoznak egy újabb levelet, melybe a túlcsordult levélből a kiemelt elemtől nagyobb kulcsbejegyzések kerülnek át, s a túlcsordult levélbe csak a kiemelt elemtől kisebb bejegyzések maradnak meg. Mivel a szülő lista is túlcsordulhat ez a művelet egy rekurzív folyamatot eredményez. A listaméretet úgy választják meg, hogy az még beleférjen a memóriába. Mivel így rendszerint sok bejegyzés van egy listában, a fa mélysége, a szintek száma, alacsonyan tartható, így néhány blokk olvasása elegendő a rekord megtaláláshoz. A szintek száma egyébként csak logaritmikusan nő a rekordszám függvényében. Ez az indexelési módszer tekinthető az egyik leghatékonyabb módszernek. Az indexelés feladatát még annyi bonyolíthatja, hogy esetleg több mező szerint kívánunk indexelni, vagy éppen nem kulcs mező szerint kívánjuk az indexelést elvégezni a lekérdezések jellegét figyelembe véve. Ha egy mezőnél egy érték több rekordban is előfordul, akkor nem szokás minden ilyen értéket külön felvenni az indexlistába, hanem csak egyet, az első előfordulást, s a többi rekord ebből a rekordból kiinduló láncolt listán keresztül érhető el.
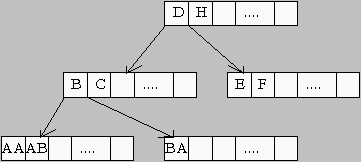
Ábra 2 Ha több mező szerint kívánunk indexelni, s az egyes indexeket valamilyen módon szeretnénk összevonni, illeszteni, akkor kapjuk a többdimenziós indexszerkezeteket. Ennek egyik lehetséges megvalósítása többdimenziós indexfa, melyben az egyes szintek ciklikusan az egyes mezőkhöz vannak rendelve. A keresés elve pedig megegyezik az egydimenziós keresőfa elvével, azzal a különbséggel, hogy minden szinten más-más mező szerint történik az elágazás. - Hashing Az indexszerkezetek révén nagyon gyorsan meghatározható a rekordok pozicója, csupán az indexlistákat kell átolvasni. Még jobb lenne, ha sikerülne még ezt a munkát is megspórolni. Erre irányulnak a hashing elérési módszerek, amikor a rekord pozícióját közvetlenül a rekord kulcsértékéből határozzák meg, tehát csak egy blokkolvasásra van szükség a rekord eléréséhez. Sajnos azonban nem mindig igaz, hogy egy blokkolvasás elég, ez csak ideális esetben valósul meg. A hash elérési módszer alapelve, hogy a kulcs értékéből valamilyen egyszerűbb eljárással, a h() hash függvénnyel meghatároznak egy pozíciót. Numerikus kulcsok esetén a h(x) = x mod n egyszokásos hash függvény, ahol x a kulcs érték és n hash tábla rekeszeinek a darabszáma. A h(x) megadja, hogy mely rekeszbe tegyük le az x kulcsú elemet. Mivel a hatékony kezelhetőség végett a lehetséges pozíciók darabszáma lényegesen kisebb a lehetséges kulcs értékek darabszámánál, így szükségszerűen több kulcsérték is ugyanazon címre fog leképződni. Egy címhez rendelt tárterületet szokás bucket-nak is nevezni, mely lemez esetében rendszerint egy blokknak felel meg. Ha több rekord kerül egy címre, mint amennyi egy bucketban elfér, akkor lép fel a túlcsordulás jelensége, amikor is egy újabb blokkot, területet kell a címhez hozzákötni. Tehát egy címhez több különálló terület is tartozhat, melyeket láncolással kötnek össze.
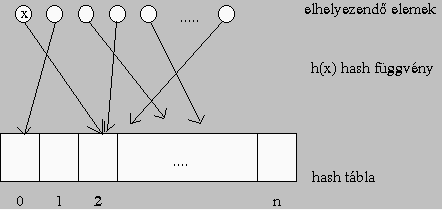
Ebben az esetben a rekord kereséséhez több blokkot is át kell nézni, amely lényegesen csökkenti a hash elérési módszer hatékonyságát. A túlcsordulás mellett a hash módszer másik hátránya, hogy csak nagyon körülményesen lehet vele megvalósítani a rekordok kulcs szerint rendezett listájának előállítását, hiszen a hash módszer az egymást követő rekordokat tetszőlegesen szétszórhatja a címtartományon a kiválasztott hash függvénytől függően. A jó hash függvény a túlcsordulást rekordok egyenletes elosztásával tudja kivédeni. Mivel a rekordokhoz rendelt címek eloszlása nagyban függ a kulcsértékek eloszlásától, a túlcsordulás soha sem védhető ki teljesen. A fileszerkezetek rövid áttekintése is világosan érzékelteti, hogy mennyi mindent kell figyelembe venni és milyen összetett lehet az optimális szerkezet megválasztása. Pedig ez a rész csak egy kis töredéke az optimális adatkezelő program tervezése során felmerülő problémák közül, hiszen nem említettük a többi komoly kérdést, mint pl. a konkurens hozzáférés, védelem, integritásőrzés. Talán érzékelhető, hogy milyen reménytelen vállalkozásnak tűnik, megfelelő fejlesztőkapacitás és idő hiányában, a minden igényt kielégítő információs, adatfeldolgozó rendszerek nulláról induló, hagyományos, pl. C nyelven történő kifejlesztése. Ez olyan mennyiségű munka, amit csak a legnagyobb szoftverfejlesztő cégek tudnak elvégezni. Mi marad hát a többieknek? Adatbázisrendszerek, adatbázis és adatbáziskezelő fogalmai A világon nagyon sok és egymástól nagyon különbözően működő információs rendszer létezik. A különbözőség ellenére azonban az is észrevehető, hogy mindegyikben az adatok kezelése szinte ugyanolyan módon, funkciókkal zajlik. A szokásos funkciók közé tartozik az adatok felvitele, törlése, módosítás és lekérdezése. Az adatok formálisan azonos kezelése tette azt lehetővé, hogy a nagyobb cégek előállítsanak olyan keretrendszert, amelyek beépíthetők a legkülönbözőbb információs rendszerekbe az adatok karbantartására. A nagytömegű adatok feltételeknek eleget tévő kezelését biztosító rendszereket adatbáziskezelő rendszereknek nevezik. Maga az adatbáziskezelés fogalma sem egy egzaktul definiált fogalom, így a mostani értelmezést egy bevezető értelmezésnek teinthetjük, melyet a későbbiekben még pontosítanifogunk. Az adatbáziskezelő rendszerek piaca pedig igen tekintélyes piac, s a jövője is igen ígéretesnek mutatkozik. Az adatbáziskezelő rendszerek forgalma az előrejelzések szerint ezen évtizedben öt év alatt megduplázódik, s a fejlesztő eszközök piacán a teljes forgalom mintegy 37 százalékát birtokolja. A legnagyobb adatbáziskezelő rendszert gyártó cég, az Oracle az előkelő harmadik helyet foglalja el a szoftverértékesítés piacán. Az Oracle jelentése szerint a cég árbevétele 1997-ban a fantasztikusnak tűnő 37%-kal növekedett. Mindez azt mutatja, hogy az adatbázisok iránti igény egyre fokozódik. Ezzel összecseng az a tapasztalat is, hogy a programozói álláskínálatokban egyre többször igényelnek relációs adatbáziskezelési, SQL ismereteket. Természetesen az adatbáziskezelő rendszerek sem hirtelen, minden előzmény jelentek meg a piacon, a köztudatban. A számítógépeket megjelenésük után a tárak kis kapacitása miatt elsősorban numerikus számítások elvégzésére használták. Később a technológia fejlődésével mind nagyobb mennyiségű információ tárolására váltak alkalmassá, s megjelentek a kimondottan a nagymennyiségű adatok hatékony kezelésére készült rendszerek is. Az első szekvenciális fileok még az 1940-es évek végén jelentek meg. Az első nem szekvenciális hozzáférést biztosító filerendszert 1959-ben fejlesztették ki az IBM-nél. Az 1960-as években egy sor új, harmadik generációsnak nevezett programozási nyelv jelent meg, mint a Fortran, Basic, PLI, melyek között volt egy, mely kimondottan adatkezelés orientált céllal jött létre, a Cobol. Egyes statisztikák szerint még pár évvel ezelőtt is az alkalmazások többsége ezen a nyelven készült, megelőzve a C, C++ nyelvet is, melyet inkább rendszerfejlesztésre használnak. Nemsokkal ezután megjelentek az első adatbáziskezelő rendszerek is. Az 1961-es évben dolgozták ki a hálós adatmodell alapjait, majd nemsokkal rá megjelent a hierarchikus adatmodell is. Az első hálózatos, konkurens hozzáférést biztosító adatbank 1965-ben jelent meg az IBM-nél, s a SABRE nevet kapta. Az adatbáziskezelő rendszerek maguk is jelentős fejlődésen mentek keresztül azóta, jelentősen megváltozott használati módjuk, az általuk támogatott adatmodell jellege. Az induló időszak hierarchikus, majd hálós adatmodelljei után az 1970-es években indult el hódító útjára a ma legelterjedtebb adatbáziskezelő típus, a relációs adatbáziskezelés. Az adatbázisokkal kapcsolatos elméleti kutatások is megszaporodtak, az 1970- es években indultak be a VLDB és a SIGMOD konferenciák. Az 1980-as években a relációs adatbáziskezelők SQL kezelő felülete is szabvánnyá vált, s megjelentek a relációs adatbázist kezelő alkalmazások hatékony fejlesztését szolgáló negyedik generációs, 4GL rendszerek is. Évtizedünkben az adatbáziskezelés területén is tért hódítanak az új elvek, mint az objektum orientáltság vagy a logikai programozás, s a hálózatok elterjedésével az osztott adatbáziskezelők szerepe is egyre nő. Emellett napjainkban egyre nagyobb szerepet kapnak az ismertetett adatszerű információkezeléstől eltérő felépítésű és funkciójú, szövegszerű kezelést megvalósító információs rendszerek is, melyek tágabb értelemben kapcsolhatók az adatbáziskezelés területéhez.

3. ábra E rövid kis történelmi áttekintés után nézzük meg most már pontosabban mit értük adatbáziskezelés alatt és mik az ide csatlakozó legfontosabb fogalmak. Első alapvető fogalmunk az adatbázis fogalma. A fogalom definícióját az adatbázisokhoz rendelhető legfontosabb tulajdonságok megadásával írhatjuk le. Ha az irodalomban utánanézünk, hamar rájövünk azonban, hogy nincs egy egységesen elfogadott definíció az adatbázis fogalmára, úgymond mindenki szabadon értelmezheti, hogy mit érez fontosnak az adatbázis fogalmára. Ezek a definíciók szerencsére, néhány kivételtől eltekintve, nem mondanak ellent egymásnak, inkább más-más aspektust hangsúlyoznak. A sokszínűség bemutatására előbb következzék néhány válogatás a lehetséges, megadott definíciókból, majd megadjuk a saját definíciónkat is, ezzel is bővítve a rendelkezésre álló választékot. Elsőként egy olyan példa következzék, melyet nem ajánlok elfogadásra, annak túl általános volta miatt: - Az adatbank rekordok összessége ('Eine Datenbank ist eine Sammlung von Datensaetzen', részlet egy Works leírásból). Ez a definíció nem tesz különbséget a normál file és egy adatbázis között, pedig nem minden file tekinthető adatbázisnak. A Oxford értelmező szótár megfogalmazása sem igazán elfogadható számunkra: - Adatbázis: Általában és szigorúan véve olyan adatállomány (data file), amely egy adatbáziskezelő rendszerrel hozható létre és érhető el. Ez lényegében áttolja a definíciót az adatbáziskezelőre, másrészt ebből úgy tűnhet, hogy minden file külön adatbázis, pedig mint látjuk ez nem igaz, több file együtt fog sok esetben egy adatbázist jelenteni. A következőkben már tankönyvekből vett definíciókat olvashatunk. - Adatbázis összetartozó és kapcsolódó adatok rendszere. (Elmasri - Navathe) A fenti definíció túl általánosan fogalmaz, így átöleli az adatkezelés szinte teljes területét, ezért önmagában nem fogadható el. A szerzők maguk is pontosítják az értelmezést a definíció után egy tulajdonságlistájával. A definíció viszont jó példa arra, hogy megmutassa, hogy az adatbázis magja az adatok és a közöttük fennálló kapcsolatok együttes tárolása. - Adatbázisokon voltaképpen adatoknak kapcsolataikkal együtt való ábrázolását, tárolását értjük. (Horváth Katalin - Dr. Szelezsán János) Itt már láthatóan nem a formai megjelenést emelték ki, hanem a helyesen a belső tartalmi vonatkozás kerül előtérbe. Számunkra leglényegesebb mondanivalója ennek a definíciónak, hogy a valóság modellezésénél nem elegendő pusztán csak az egyedeket letárolni, hanem az egyedek között fennálló kapcsolatok nyilvántartása is fontos. Mit érne egy olyan rendőrségi nyilvántartás, melyben mind az autók, mind az állampolgárok adatai benne vannak, de a rendszer nem tárolná, hogy melyik autó kinek a tulajdona. A kapcsolatok a valóságmodell szerves részei, és az adatbázisnak ezen kapcsolatokat is tárolnia kell. Még egy kicsit többet mond a következő definíció: - Az adatbázis véges számú egyed-előfordulásnak, azok egyenként is véges számú tulajdonságértékének és kapcsolat-előfordulásainak az adatmodell szerint szervezett együttese. (Dr. Halassy Béla) E megfogalmazás lényeges és új eleme, hogy az adatok azért nem tetszőleges formátumban tárolódnak, hanem minden adatbázisnak van egy belső logikai struktúrája, melybe be kell illeszkedni minden tárolt adatnak. Ilyen struktúrára, vagy adatmodellre több példát is láttunk a történelmi áttekintésben, pl. a relációs adatmodell is szerepelt. Mind majd később látni fogjuk ez nem fizikai struktúrát jelent első sorban, hanem logikait. A következő definíció a neves amerikai szakértőtől származik: - Az adatbázis a felhasználók által rugalmasan kezelhető adatok rendszere. (C.J. Date) A definíció lényeges mondanivalója, hogy az adatbázisban tárolt adatok többen, viszonylag rugalmas keretek között, tehát nem csak megszabott módon, használhatják. Végül az utolsó példa is hasonló elemeket emel ki: - Az adatbázis összetartozó adatok azon rendszere, mely megosztott több felhasználó között, és az elérést egy központi vezérlő program szabályozza, és a felhasználónak nem kell ismernie az adatok fizikai tárolási mechanizmusát. (J. G. Hughes) Itt is történik utalás a logikai modell és a fizikai tárolás különbségére, valamint a konkurens hozzáférésre. Az előző példák és a bevezetőben említettek alapján felállíthatunk egy összesítő definíciót az adatbázis fogalmára. Mindenekelőtt nézzük meg mit kell tárolni az adatbázisban. Nyilvánvaló, hogy a modellezett valóságban szereplő egyedeknek és kapcsolataiknak szerepelniük kell. A felhasználó ezekkel az adatokkal fog dolgozni, ezen adatok kezelésére készülnek a különböző felhasználói programok. Ezeket az adatokat szokás tényleges, elsődleges adatoknak is nevezni. Az adatkezeléssel szemben felállított követelmények kielégítéséhez ezen adatok önmagukban nem elegendőek, gondoljunk csak arra, hogy a hatékony adatkeresés vagy indexstruktúrát vagy hash szerkezetet igényel, vagy például az adatvédelem biztosításához szükség van a hozzáférési jogok tárolására és az adatmásolatok megőrzésére. Ezek a szerkezetek az elsődleges adatokra vonatkozó információkat tárolnak, ezért nevezik ezen adatokat metaadatoknak is, tehát adatokra vonatkozó adatoknak. Következzék tehát a definíció: Adatbázis: egy olyan integrált adatszerkezet, mely több különböző objektum előfordulási adatait adatmodell szerint szervezetten perzisztens módon tárolja olyan segédinformációkkal, ún. metaadatakkal együtt, melyek a hatékonyság, integritásőrzés, adatvédelem biztosítását szolgálják. Az adatbázis szó rövidítésére gyakran használják az angol rövidítését, a DB-t. Az adatbázisok elvileg tetszőleges méretűek lehetnek. Az elsődleges adatok száma a nullától, az üres adatbázistól a végtelen értékig terjedhet. Az elméletileg végtelen kapacitást a gyakorlatban a rendelkezésre álló hely, vagy éppen a belső tárolási struktúra korlátozza. Az adatbázis mint a fentiekből kitűnik, egy összetett adatstruktúrának tekinthető. Az adatstruktúra viszont az alkalmazások passzív elemit jelentik, s kell egy algoritmus, egy program mellyel felhasználhatók ezek az adatok, életre kelthetők az információk. Így az adatbázishoz kapcsolódnia kell egy kezelő programnak, amit adatbáziskezelőnek neveznek. Az adatbáziskezelő rendszer értelmezése jóval egységesebb, mint az adatbázis értelmezése volt. Egy általánosan elfogadott definíciónak tekinthető a Coad által megadott értelmezés, mely szerint az adatbáziskezelő rendszer az a program, mely az adatbázishoz történő mindennemű hozzáférés kezelésére szolgál. Forsthuber anyagában egy részletesebb felsorolás is található, hogy milyen feladatok elvégzésre szolgál az adatbáziskezelő rendszer, nevezetesen - adatbázisok létrehozására - adatbázisok tartalmának definiálására - adatok letárolására - adatok lekérdezésére - adatok védelmére - adatok titkosítására - hozzáférési jogok kezelésére - fizikai adatszerkezet szervezésére A felsorolás alapján érzékelhető, hogy a hozzáférés nem egy egyszerű írási vagy olvasási műveletet jelent, hiszen az adatbáziskezelő rendszernek kell gondoskodnia a már korábban említett integritási, hatékonysági és védelmi feltételek megőrzéséről. Az adatbáziskezelő rendszer emiatt egy bonyolult programrendszernek tekinthető, mely sok funkcióját, összetettségét tekintve leginkább az operációs rendszerekhez hasonlítható. Az integritási, hatékonysági és védelmi feltételek ellenőrzését és betartatását az adatbáziskezelő rendszer a háttérben végzi el, mintegy a felhasználó közvetlen parancsa vagy éppen tudta nélkül. Mindez azért történik így, hogy a felhasználó véletlenül vagy szándékosan se tudja elrontani az adatbázist. Az adatbázis helyességének megőrzésének fontossága miatt definíciónkban külön kiemeljük az adatbáziskezelő rendszer ezen tulajdonságát: Adatbáziskezelő rendszer: Az a programrendszer, melynek feladata az adatbázishoz történő hozzáférések biztosítása és az adatbázis belső karbantartási funkcióinak végrehajtása. Az adatbáziskezelő rendszer rövidítése az angol elnevezés alapján: DBMS. A DBMS és az operációs rendszer hasonlata annyiban is helytálló, hogy mindkettő egy alsó szoftverréteget valósít meg, a felhasználó nem közvetlenül, hanem segédprogramokon keresztül éri el. Az adatbáziskezelés esetében is a felhasználó nem közvetlenül a DBMS-t kezeli, hanem egyéb segéd- és alkalmazói programokat futtat, melyek majd a DBMS-en keresztül érik el az adatbázisban tárolt adatokat. Maguk a DBMS rendszereket forgalmazó cégek is készítenek ilyen segédprogramokat, de egyedi fejlesztéssel is létrehozhatunk adatbázisbeli adatokat kezelő programokat. A DBMS-hez integráltan tartozó segédprogramok angol rövidítése UIT (User Interface Tools). Ezek alapján egy hatékony adatkezelő rendszernek tartalmaznia kell egy adatbáziskezelőt, egy adatbáziskezelő rendszert, valamint alkalmazói és segédprogramot. Az adatbáziskezelő, az adatbáziskezelő rendszer, valamint alkalmazói és segédprogramok együttesét adatbázisrendszernek neveznik, melynek rövidítésére a DBS használják. A DBS-en belül az alkalmazói és a segédprogramok állnak legközelebb a felhasználóhoz. A felhasználó ezzel a komponenssel kommunikál. A kiadott utasítások értelmezése után az adatkezelésre vonatkozó részlépéseket a program a DBMS felé továbbítja. Ezekután a DBMS elvégzi a megfelelő adatbázis módosításokat vagy adatbázis olvasási műveleteket, s az eredményt továbbítja az alkalmazói program felé. Ezen munkamegosztáson alapuló hierarchiát szemlélteti a 4. ábra is.
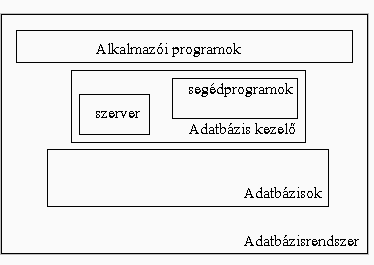
4. ábra A segédprogramok között kiemelt helyen szerepelnek a felhasználók egy szűk, kiemelt csoportjának készült programok. Ez a csoport annyiban játszik kiemelt szerepet, hogy az ő feladatuk az adatbázis menedzselése. Ehhez kiemelt jogosultságokkal rendelkeznek, s csak ezen jogosultságokkal lehet számos adminisztrációs műveletet elvégezni, mint pl. a fizikai tárolási struktúra szabályozása, jogosultságok kezelése. Ezen funkciók elvégzésére alkalmas segédprogramok természetesen megfelelő módon, pl. jelszóval védettek a jogosulatlan hozzáférés ellen. Ezen jogokkal felruházott felhasználókat nevezik adatbázis adminisztrátoroknak (rövidítése DBA). Az adminisztrátorok mellett dolgoznak az operátorok, feladatuk a rutinszerű rendszertevékenységek elvégzése, mint pl. a mentések, rendszerindítások vagy zárások végrehajtása. A felhasználóknak egy tágabb csoportja az alkalmazásfejlesztők köre. A fejlesztőknek a DB oldaláról ismernie kell az adatbázis adatmodelljét, a metaadatok megadásának módját, az alkalmazói programok fejlesztésének lehetőségeit, hogy csak a legfontosabb követelményeket említsük. A fejlesztők egyik csoportja az adatbázis tervezésével foglalkozik, míg a másik csoportjának a felhasználói programok megírása, tesztelése a feladata. A felhasználók legnépesebb csoportja az alkalmazók köre, akik az elkészült alkalmazásokat használják, számukra az adatbázis azon adatokat jelenti, amelyekkel az alkalmazások során találkoznak, az adatbázis vagy a DBMS létezéséről, vagy netán belső működéséről semmilyen ismerettel sem kell rendelkezniük. Az adatbázisrendszer mellett az adatkezelés másik fő variánsa a hagyományos file kezelő rendszer. Ez a fajta adatkezelési technikai is elterjedt, használata bizonyos esetekben előnyösebbnek bizonyul a DBS alkalmazásánál. A rendszerfejlesztő egyik fontos feladata a megfelelő adatkezelési módszer kiválasztása, annak eldöntése, hogy mikor érdemes DBS-t és mikor file kezelő rendszert használni. A döntés helyes meghozatalához ismerni kell mindkét rendszer előnyeit és hátrányait is. A DBS-t illetően részben az előzőekben ismertetett fogalmakon alapulva az alábbi előnyök emelhetők ki: - Az egyedtulajdonságok, kapcsolatok és metaadatok egységes tárolási rendszere. Az adatbázis nem egy speciális alkalmazói programhoz készült, hanem tetszőlegesen sokfajta alkalmazói program is futhat rajta, több alkalmazói program adatait is összefogja. Ezért szokás az adatbázisban tárolt adatokat integrált adatoknak is nevezni. A normál filekezelésnél ezzel szemben rendszerint minden alkalmazói programhoz el kell készíteni a saját adatrendszerét. - Adatfüggetlenség Az adatfüggetlenség kérdése az egyik legfontosabb jellemzője az adatkezelés fejlődésének. A 1950-es évek elején megírt adatkezelő programok egyik jellemzője volt, hogy a programkód teljes mértékben tükrözte az adatok tárolásának szerkezetét, hiszen a program szinte közvetlenül elérhette az adatokat. Ezt a fejlettségi szintet nevezik a teljes adatfüggőség korának. Ezt azt is jelentette, hogy ha megváltozott a fizikai struktúra, akkor át kellett írni a programot is. Mivel a hardware gyors fejlődése miatt erre gyakran szükség volt, a fejlődés következő lépcsőjében beépült egy filekezelő rendszer az operációs rendszerbe, s az alkalmazás már egy átdolgozott, áttranszformált képet kapott a fileszerkezetről. A programban egy logikai adatszerkezetet kell csak definiálni, a fizikai szerkezetre való leképzést a konverter végzi. A fizikai adatfüggetlenség azt jelenti, hogy a fizikai adatszerkezet, az elérési mód megváltoztatható anélkül, hogy a programot is módosítani kellene. A mai hagyományos filekezelésnél egy rekord szintű függetlenség valósul meg, hiszen a állományt sima rekordsorozatnak képzelhetjük el, pedig valójában nem az, ezzel szemben a rekord mezőit úgy kell megadni, ahogy azok fizikailag is megvalósulnak. Az adatfüggetlenség következő, az adatbázisokban megvalósuló szintje a mezőszintű fizikai adatfüggetlenség, hiszen az adatbázisban az egy rekordba tartozó mezők is fizikailag szétszórtan helyezkedhetnek el az adathordozón. Az adatfüggetlenség másik típusát logikai adatfüggetlenségnek nevezik, mely szintén megvalósul az adatbázisoknál. Ez alatt azt értjük, hogy a letárolt logikai adatmodell maga is bővíthető, illetve bizonyos mértékben módosítható, hogy az alkalmazói programokat módosítani kellene. Ha tehát egy objektumtípushoz egy újabb tulajdonságot kívánok letárolni, nem kell egyetlen egy meglévő alkalmazói programot sem módosítani. - Nagyobb adatabsztrakció A adatbáziskezelésnél az adatok a felhasználó szemszögéből tekintve adatmodellben tárolódnak, ezért a felhasználónak nem kell törődnie a fizikai tárolás részleteivel, s egy magasabb absztrakciós szinten értelmezheti az adatrendszert. A részletek rejtve maradnak a felhasználó és a programfejlesztő előtt is. - Adatmegosztás, párhuzamos hozzáférés A DBMS felkészült az integrált adatokhoz történő osztott hozzáférések kezelésére. A hagyományos filekezelő alkalmazásoknál csak igen nagy ráfordítással tudnánk biztosítani a DBMS-ben megvalósított konkurens hozzáférést támogató koncepciót. Az adatmegosztás révén a helyigény is csökkenthető, és így mindenki a legaktuálisabb adatokhoz férhet hozzá. - Ellenőrzött redundancia Mivel több alkalmazás is ugyanazt az adatbázist használja, ezért a felhasznált adatok is egy helyen, egykézben összpontosulnak. A hagyományos filekezelésnél ha több alkalmazásnak is szüksége volt egy adatra, akkor az adat több fileban is letárolásra került. Ez a redundancia számos hátránnyal járt, kezdve a felesleges helyfoglalástól a konzisztencia megőrzésének problémájáig. - Hozzáférési jogosultságellenőrzés, adatvédelem A DBMS az operációs rendszerekhez hasonlóan nyilvántartja a jogosult felhasználókat. Ennek során nyilvántartja az azonosító nevet, a jelszót, a tulajdonában lévő adatokat, az engedélyezett műveleteket. Az adatvesztés okozta károk minimalizálására mind statikus mind dinamikus védelem használható. A statikus védelem egyik eszköze a mentés, a dinamikus védelemhez pedig a naplózás tartozik. - Optimalizált fizikai adatszerkezetek A DBMS-ben implementálták mindazokat a hatékony adatstruktúrák kezelésére (mint hashing, indexelés, stb.) alkalmas algoritmusokat, melyekkel jelentősen javítható a műveletek hatékonysága, gyorsasága. Normál filekezelés esetén, nagyobb méretű adatszerkezetek esetén a programozónak kellene mindezen hatékonyabb adatstruktúrákat megvalósítania. - Integritási feltételek érvényesítése A DBS keretén belül magában az adatbázisban tárolhatjuk az adatok között fennálló integritási szabályok formájában. Az adatbázis módosításakor automatikusan ellenőrzi a DBMS, hogy nem-e sérült meg az integritási szabály. Ha megsérülne, akkor nem hajlandó elfogadni a változtatást. Mivel mindezt a DBMS végzi, nem a felhasználói programnak nem kell törődnie az integritási problémák teljességével. A hagyományos filekezelésnél a programozó vállán volt minden felelőség. - Szabványosság, hatékonyság, rugalmasság A szabványos adatmodellek és kezelő felületek, interfacek használatával az elkészült rendszer jobban érthetővé válik mások számára is, ezáltal későbbi fejlesztés, módosítások is könnyebbé válnak. A fejlesztő a DBMS-en keresztül jobban rákényszerül a szabványos eszközök használatára, mint a több szabadságot nyújtó normál filekezelésnél. Emellett az sem elhanyagolható, hogy a DBMS-ekhez számos fejlesztő eszköz áll rendelkezésre, jelentősen megnövelve a fejlesztés hatékonyságát. A szükséges változtatások gyorsabban végrehajthatók, nagyobb rugalmasságot biztosítva a rendszernek. A felsorolt előnyök ellenére vannak olyan esetek amikor célszerűbb a normál filekezelést választani. Ennek elsősorban az az oka, hogy a biztonságos, hatékony adatbáziskezelés biztosítását meg kell fizetni a felhasználónak, mely többlet időt és többlet költséget is jelent. Ezért nem célszerű adatbázist használni, ha - Az alkalmazás, az adatrendszer viszonylag egyszerű, s nem várhatók változtatások az adatrendszerben a jövőben sem. Ekkor felesleges beruházás a drágább DBMS beszerzése. - Az alkalmazás real-time követelményeket támaszt az adatrendszerrel szemben, azaz nagyon gyors adatkezelésre van szükség. Ez a DBMS összetettsége miatt nem biztosítható. - Egyfelhasználós adatrendszer esetén, amikor konkurens hozzáférés nem fordulhat elő. Ekkor maga az alkalmazás kézben tudja tartani az adatintegritás megőrzését, az adathozzáférés biztosítását. Ugyan nagyobb időráfordítással, de költségkímélőbben meg lehet oldani a feladatot a normál filekezeléssel. Ha a feltételek mérlegelésével megszületett a döntés, hogy DBS-t alkalmaznak, akkor kezdődhet el a DBS fejlesztésének igazán érdekes és izgalmas folyamata. Ennek során ki kell választani a megfelelő adatmodellt és DBMS-t, el kell készíteni a modellezett valóság megfelelő adatmodelljét, létre kell hozni az adatbázist és a szükséges alkalmazói programokat is. S a szakemberek hosszú együttes munkájának eredményeként megszülethet az igényelt adatbázis rendszer. Modellezés szerepe az adatbáziskezelésnél Az alkotó tevékenység során alapvető szerepet játszanak a különböző modellek a környező világ megértésében, leképzésében és átalakításában. A modellek teszik lehetővé a lényeg kiemelését és szemléltetését. A modell fogalma alatt rendszerint két különböző dolgot is szokás érteni: egyrészt olyan rendszert, amely a valóság egy vizsgált szeletével struktúrában vagy viselkedésben megegyezik vagy hasonló jelleget mutat fel és célja a vizsgálatán keresztül a valóság állapotára, viselkedésére vonatkozó következetések levonása. Másrészt a modell kifejezéssel jelöljük azon eszközrendszert is, amellyel az előző értelemben vett modell leírható megadható. Tehát a modell egyrészt egy jelölésrendszert, másrészt egy elkészült leírást is jelölhet. Sokféle és igen változatos modellekkel találkozhattunk már az eddigiekben. Magukat a programokat is egyfajta modellnek tekinthetjük, hiszen a vizsgált valóságot írják le a programozási nyelvek utasításainak, kifejezéseinek a segítségével. Amikor alkalmazást készítünk, több lépcsőn keresztül modellezük a feladatot. Előbb egy áttekintő leírást készítünk, melyben közérthetően, az emberi fogalmakhoz közel állóan vázoljuk fel a megoldást. Később ez alapján elkészítjük a programozási nyelv segítségével megadott leírást. Az adatbáziskezelés területén a modellezésnek még nagyobb a szerepe, mint a hagyományos programfejlesztési eszközöknél. Nézzük mi indokolja, miben jelenkezik a modellezés fontossága. A hagyományos alkalmazások egyfajta problématerületre készülnek, behatárolt funkciókkal és adatelemekkel. Egy könyvelési rendszer például nem alkalmazható könyvtár nyilvántartásra. Ezt úgy is kifejezhetjük, hogy az alkalmazásba beleégetődött a problématerület modellje. A modell megváltoztatásához újra kell írni az alkalmazás bizonyos részleteteit. Az adatbáziskezelő rendszerek ezzel szemben nemcsak egy problématerülethez készültek, hanem általános célúak. Az adatbáziskezelő rendszernek a modellezett területtől függetlenül biztosítania kell az adatbázisban tárolt adatok hatékony kezelését. Emiatt az adatbáziskezelőkbe nem lehet egyetlen egy fix modellt beégetni. A DBMS-nek nagyon sokféle különböző modell kezelésére alkalmasnak kell lennie. Ez pedig csak úgy oldható meg, ha a DBMS maga is rendelkezik egy felülettel, amelyen keresztül megadható, hogy milyen legyen az aktuálisan tárolandó adatrendszer struktúrája, modellje. Tehát a DBMS- ekhez mindíg csatlakozik egy leíró nyelv, egy modell. A hagyományos alkalmazásokhoz ezzel szemben nem rendelhető egy ilyen rugalmas modell (modell, mint leíró rendszer). A informatikában azon modelleket, amelyek az adatok struktúrájának leírására szolgálnak, adatmodelleknek nevezik. Mivel a DBMS-ekhez rendelt modell is ugyanazen célt szolgálja, ezért a DBMS-hez rendelt modell is adatmodellnek tekinthető. Az adatmodellek leírásával egy későbbi fejezetben fogunk részletesebben foglalkozni. Az adatmodellekről azonban már most is megjegyezhetjük, hogy központi szerepet játszanak az adatbáziskezelésben, hiszen ezen keresztül adhatjuk meg a megvalósítandó rendszer leírását az adatbáziskezelőnek. Ahhoz, hogy használni tudjuk az adatbáziskezelőt, ismernünk kell az adatbáziskezelőhöz tartozó adatmodellt. Mint várható, nemcsak egyféle adatmodell létezik. Az adatbáziskezelés fejlődésével újabb és újabb adatmodellek jöttek létre. A DBMS-ek egyik fő jellemzője, hogy mely adatmodellhez kapcsolódnak. A korábban már említett relációs, hierarchikus vagy hálós előtagok is az alkalmazott modellt azonosítják, azaz például a relációs DBMS a relációs adatmodellen nyugszik. Mivel az adatmodell egy jelölésrendszeren alapszik, ezért nem igényli feltétlenül egy DBMS létét, azaz vannak kolyan adatmodellek is, melyekhez nem létezik DBMS. Ennek ellenére ezen adatmodellek sem tekinthetők felesleges, selejt adatmodelleknek. Egyrészt ezen modellek rendszerint a végső DBMS adatmodell kialakításában segítenek, hiszen emlékszünk rá, hogy maga a programozás is egy többlépcsős modellezési folyamatként értelmezhető; másrészt ezek a modellek visszahatnak a DBMS-ek fejlesztésére is, s egyszer talán rajtuk alapuló DBMS-ek fognak megjelenni a piacon, mint ahogy ez a múltban már párszor megtörtént. Áttekintés az adatbázisrendszerek architektúrájáról Az előzőekben megismert alapfogalmakra építve most egy részletesebb ismertetést adunk az adatbázisrendszerek elvi felépítéséről, majd ezt követően az adatbázisok és az adatbáziskezelő alkalmazások fejlesztéséről esik szó. A bemutatandó fogalmak az adatbáziskezelés általános koncepciójának a megértését, elsajátítását szolgálják, s a gyakorlatban használatos ismeretek, részletek tárgyalására a későbbi fejezetekben kerül majd sor. Az adatbázisrendszerek belső architektúráját többféle szempont szerint is elemezhetjük. Az előző fejezetben bemutatott struktúra egy funkcionális elemzésre alapult. A három alapvető komponens, az - adatbázis - az adatbáziskezelő rendszer és - az alkalmazói vagy sedédprogramok mindegyike különböző feladatot látott el. A különbözőség a komponensek éles fizikai elkülönülésében is megnyilvánul. Az adathordozón más-más helyen, más-más azonosítóval szerepelnek, s kiemelten, külön-külön is mozgathatjuk, vagy módosíthatjuk őket. Az egyes komponensek létrehozásának idejei is elkülönülnek egymástól, és esetleg más-más helyről is szerezzük be őket. Elsőként a DBMS kiválasztása történik meg, majd ennek segítségével lehet létrehozni az adatbázist, majd az erre épülő alkalmazásokat. Személyileg is szétválnak az egyes komponensek kezelésével megbízott posztok, szükség van többek között rendszeradminisztrátorra, operátorra a DBMS kezeléséhez, a programozók és a felhasználók pedig az alkalmazásokhoz kötődnek. E szembetűnő, funkcionális szempontok szerint történő strukturálás mellett más módon is elemezhetjük az adatbázisrendszereket. A legismertebb, sőt szabványként is elfogadott strukturálás, az ANSI/SPARC architektúra néven ismert struktúra. Nevét onnan kapta, hogy az ANSI/SPARC Study Group on Data Base Manegement Systems bizottság dolgozta ki. A bizottságot az 1970- es évek elején hozták létre az ANSI szabványosítási hivatalkeretében, hogy meghatározza az adatbáziskezelés azon területeit, melyben lehetséges és célszerű a szabványosítás. A vizsgálat eredményeként megszületett egy általános DBS modell, melyben kiemelt hangsúlyt kaptak az egyes komponensek közötti interface-ek. Az ANSI/SPARC architektúra a adatbázis leírására három szintet tartalmaz: az külső (external), a koncepcionális (conceptual) és a fizikai (internal) szintet.
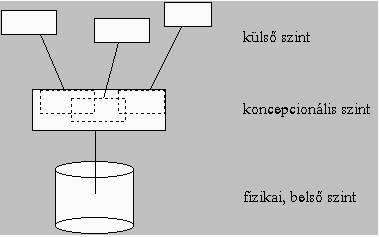
5. ábra Az egyes szintek az adatbázisrendszer, mint egység, különböző megvilágításainak, megközelítéséinek felelnek meg. Ezért a szinteket szokás nézeteknek (view) is nevezni. A külső szint foglalja magában mindazt, amit egy-egy felhasználó az adatbázisból lát, amit a felhasználó adatbázis alatt gondol, ami ő számára az adatbázist jelenti. Ez az egy egyedi látásmódok összessége. Mivel egy adatbázisrendszerhez több alkalmazó, felhasználó is kapcsolódhat, ezért több ilyen nézetet is tartalmazhat. Ezek a nézetek rendszerint különbözőek, hiszen a felhasználók a teljes adatbázis más-más részletét látják csak. Így például más adatokat kezel, más adatokhoz férhet hozzá a teljes vállalati adminisztrációs rendszeren belül egy pénzügyi vagy egy személyzeti adminisztrátor. Mivel az adatrendszer más elemeivel ők soha nem kerülnek kapcsolatba, ezért számukra ezek az adatok jelentik a teljes adatbázist, ők úgy látják, hogy az adatbázis csak azokat az adatokat tartalmazza, melyekkel kapcsolatba kerülnek. Az egyes nézetek különbözősége azonban nem zárja ki azt a lehetőséget, hogy egyes nézeteknek közös elemei is legyenek. Ugyan sok, különböző külső nézet létezik, de ezek mindegyike valójában ugyanannak az adatbázisnak a különböző részleteit tartalmazza. Ezért értelmezhető az a látásmód is, mely a teljes adatbázist tartalmazza. Egy ilyen nézettel kell rendelkeznie például a rendszeradminisztrátornak, vagy az adatbázistervezőnek is. Ezt a közösségi nézet a koncepcionális szinten helyezkedik el. A közösségi nézetből viszont csak egy van, s az összes külső nézet ennek egy szeletét jelenti. A felhasználó a külső nézetében a modellezett valóság egyedeit, egyedkapcsolatait látja, még az adatbázistervező a DBMS által támogatott adatmodellben, tehát egy absztraktabb leírásban gondolkodik, addig az adatbázis végül is fizikailag is létezik, valamilyen fizikai adatstruktúrában letárolva az adathordozón. Mint már láttuk, a kiválasztatott adatstruktúra is lényeges szerepet játszik az adatbázis hatékonyságánál, s az adatbázis adminisztrátor éppen egyik feladata a megfelelő fizikai struktúra kialakítása, hangolása. Tehát létezik egy, a fizikai tárolási szerkezethez közel álló nézet is, melyet adattárolási nézetnek neveznek, és ez a belső szinten helyezkedik el. Ez a három szint, mint láttuk, az adatbáziskép absztrakciós szintjében is különböznek egymástól. Erre az absztrakciós szintkülönbségre a számítástechnika más területeiről is hozhatunk példát. Amikor egy közgazdász egy termelésoptimálási programot használ, akkor abban a gépkapacitásokat például egy mátrixban letárolva látja maga előtt. A programozó számára az adatok egy tömbben letárolva jelennek meg. Fizikailag pedig azonos hosszú rekeszek sorozataként tárolódnak az adatok. Annyiban is használható ez a hasonlat, hogy az adattárolási nézet is egy folytonos tárolást tételez fel, s nem törődik az adatok blokkokba történő tördelésével, a blokkok láncolásával. Az egyes szinteken a nézetek megadása különböző adatmodellek segítségével történik. Ennek során meg szokták különböztetni magát a nézetet, vagyis azon adatokat amit látok, az adatok tárolási struktúrájától, az adatszerkezettől. Az adatszerkezet leírását sémának (schema) nevezik. Egy ház esetén a tervrajz mint szerkezeti leírás, séma szerepelhet, s maga a tervnek megfelelő szerkezettel elkészült ház lehet a nézet. A séma mondja meg például hogy van egy kút a kert sarkában. A megvalósulás pedig már egy konktét kútat tartalmaz. A különböző megvalósulásoknál a kút más és más alakban jelenhet meg. Mint ahogy több ház is felépülhet egy tervrajz alapján, ugyanúgy több nézet is létrejöhet egy séma alapján. Az adatbázis tervezésekor elsőként a sémákat kell létrehozni, s ez a váz töltődik fel a használat során adatokkal. A séma alapján felépülő konkrét adatrendszert séma megvalósulásnak, adat-előfordulásnak, angolul instance-nek nevezik. A sémák megadására valamilyen sémaleíró nyelvet. modellt lehet használni, s mivel a sémák elsődlegesen adatszerkezet definíciókként értelmezhetők, ezért, ezt a nyelvet adatdefiníciós nyelvnek is nevezik, s a DDL (Data Description Language) rövidítést használják a jelölésére. A hagyományos programozási nyelvekben is találkozhatunk DDL elemekkel, mint pl. az int, struct, array, stb. kulcsszavak, melyek többé vagy kevésbé helyileg is elkülönülnek a vezérlési nyelvelemektől. Az adatbáziskezelésnél, mint majd látni fogjuk ez az elkülönülés élesebb a hagyományos nyelveknél megszokottól. Mivel a séma csak váz, melyet majd adatokkal kell feltölteni, szükség van olyan eszközre is, mely lehetővé teszi az adatok kezelését. Az ilyen adatkezelési utasításokat végrehajtására szolgáló kifejezések alkotják az adatkezelő nyelvet, melynek rövidítése DML (Data Manipulation Language). A hagyományos programozási nyelveknél a jól megismert read, write stb. utasítások sorolhatók a DML-hez. A programok készítésénél szokásos vezérlési szerkezetek, mint ciklusszervezés vagy elágazások, létrehozására szolgáló nyelvi elemek is megtalálhatók a legtöbb DBMS-nél, habár ezek viszonylag lazábban kötődnek a DBMS-hez, annak elsődleges adatorientáltsága miatt. E laza kapcsolatot mutatja, hogy a számos DBMS nem is tartalmazott procedurális nyelvet, hanem csak egy adatkezelő, adatdefiníciós résznyelvet, melyet egy hagyományos programozási nyelvvel együtt lehetett az alkalmazások elkészítésére felhasználni. A hagyományos programozási nyelvet nevezték gazda (host) nyelvnek, s ebbe kellett beültetni az adatkezelő és adatdefiníciós utasításokat. A gazda nyelv és DB kezelő nyelv közötti kapcsolatot lazának nevezik, ha élesen elkülönül egymástól a két nyelv a programon belül, mint azt a következő példa is mutatja: if (a > 8) { EXEC SQL INSERT INTO A VALUES (3); b = 3; } Ebben rögtön látható, hogy van benne és hol DML utasítás. A szoros kapcsolat ezzel szemben azt jelenti, hogy az adatbázis DML utasításai közvetlenül nem érzékelhetők, minden adatkezelő utasítás megfelel a gazda nyelvben megadott szintaktikának. A szoros kapcsolatban rejlő nehézségek miatt napjainkban még csak a laza csatolás terjedt el. Az egyes nézetekben az adatok egyedekhez kötődve jelennek meg, ahol az adatbázis több előfordulását is tartalmazza egy egyedtipusnak. Itt az egyedtipus alatt az egyed leírására szolgáló sémát értjük, pl. egy könyv egyed esetén a könyvtári nyilvántartásban a séma egy címet, ISBN számot, egy leltári számot, kiadót, szerzőt tartalmazó rekordszerkezetként is elképzelhető. A rendszerben minden könyvet azonos szerkezettel, a könyvtipussal írunk le. Az egyes könyvek lesznek a könyv előfordulások. Az egyedelőforduláshoz tartozó adatokat szokás rekordnak is nevezni. Az ANSI/SPARC architektúra különböző szintjein egy egyed rekordjai más-más alakot ölthetnek. A külső szint rekordjai különbözhetnek egymástól az egyes nézetekben, illetve lehetnek ezen rekordoknak közös elemei is. A koncepcionális szinten létezik egy olyan koncepcionális rekord, mely az egyes külső rekordok mezőinek egyesítését tartalmazza. A fizikai szint rekordja szintén különbözhet a logikaitól, hiszen a koncepcionális rekord fikailag lehet partícionált vagy éppen tartalmazhat duplikált elemeket is. A rekord mindig egy egyedelőforduláshoz tartozik, miközben az adatbázis több előfordulást is tárolhat. Az adatbázis tehát tartalmazza az egyedeket, mint önálló egységeket, és az egyedösszességet, mint csoportot. Ebből eredően az egyedeket kezelhetjük csoportosan és egyénenként. Ezt a kétfajta megközelítést halmazorientált és rekordorientált megközelítésnek nevezik. A műveletek is lehetnek ennek megfelelően rekordorientáltak vagy halmazorientáltak. Egyes DBMS-ek különbözhetnek egymástól abban is, hogy mely megközelítést támogatják. A szintek sémáinak és nézeteinek különbözőségéből következik, hogy az egyes szintek kapcsolódásánál leképezést, illesztést kell végezni. Az egyes szintek között pedig igen intenzív kapcsolat áll fenn. Hiszen amikor egy alkalmazás, egy felhasználó kiad egy utasítást, akkor azt a saját külső sémájában fogalmazza meg. Egyidőben több ilyen utasítás keletkezhet, melyek mindegyike más-más külső sémát használhat. A műveletek összehangolására, vezérlésére minden utasítást le kell fordítani a koncepcionális szint sémájára. A fizikai szintű műveletek elvégzéséhez ismerni kell az adatok fizikai sémáját is, tehát szükség van a koncepcionális és a fizikai séma közötti leképzésre is. A fizikai művelet elvégzése után az eredmény visszajuttatásához ugyanígy el kell végezni a leképzéseket, csak most fordított irányban. A leképzések, melyek egyértelműen megnövelik a műveletek végrehajtási idejét, legfontosabb célja a már korábban említett függetlenség biztosítása. Maga a felvázolt ANSI/SPARC architektúra is az adatbáziskezelésben megvalósuló adatfüggetlenség megnyilvánulása is, hiszen a felhasználó, az alkalmazásfejlesztő függetlenítheti magát a többi alkalmazástól, a koncepcionális tervezés pedig függetlenítheti magát a fizikai, belső megvalósulástól. A leképzések elvégzése az elmondottakból következően csak a DBMS feladata lehet, hiszen az egyes alkalmazói programoknak nem kell ismerniük a teljes adatbázist, a koncepcionális sémát. A DBMS központi szerepe indokolja, hogy egy kicsit részletesebben is foglalkozzunk az általa elvégzett tevékenységekkel, belső struktúrájával. A DBMS, mint már említettük, mindkét másik DBS komponenssel, a DB-vel és az alkalmazói programokkal is kommunikál. Az adatbázishoz, mint a külső adathordozón letárolt fizikai adatszerkezethez történő hozzáféréshez a DBMS is felhasználhatja a hardware fölött elhelyezkedő operációsrendszer IO szolgáltatásait. Így a DBMS tehermentesíthető lesz az alacsony szintű IO műveletek végrehajtása alól, s egyszerűbbé válik a DBMS implementálása is. E feladat-átruházásból egyrészt az is következik, hogy a DBMS valójában nem közvetlenül a DB-vel, hanem az OS-sel áll kapcsolatban, másrészt az is érzékelhető, hogy a DBMS hatékonyságát az OS-hez történő illesztése is számottevően befolyásolja. A probléma fontosságát mutatja, hogy számos kutatási program témája a kapcsolódás hatékonyságának növelése, s már több javaslat is született a DBMS-OS kapcsolat javítására. Egy, ma még rendszerint meglévő gyenge pont a kétszintű tárolási architektúra (two levels storage) használata. Ebben az elnevezésben a kétszintűség arra utal, hogy a DBMS-nek nyilván kell tartania, hogy mely rekordjai, blokkjai találhatók meg a memóriában, s melyek vannak kint a lemezen, tehát különbséget tesz a belső és a külső tárolás között. Erre azért is szükség van mivel a DBMS az OS-től eltérő módon értelmezi az adatállományok belső struktúráját, a DBMS elemi tárolási egysége különbözik pl. az OS IO elemi egységétől, így a legtöbb DBMS saját file és bufferkezeléssel rendelkezik, melyek felhasználják az OS elemi IO szolgáltatásokat. Egy hatékonyabb megoldást jelent ezen a téren az egyszintű tárolás (single level storage) alkalmazása, melynek lényege, hogy a felhasználói processz elől elrejtsék a fizikailag meglévő tárolási struktúra megosztottságát, ami a memória és háttértár különböző kezelési módjából ered. Ebben az esetben a DBMS összes adata egyetlen egy hatalmas virtuális címtartományban helyezkedik el, ezzel egységessé válna az adatelemekre történő hivatkozás, függetlenül attól, hogy fizikailag hol helyezkedik el, nem a DBMS-nek kellene nyilvántartania, hogy a rekord most éppen benn van-e a memóriában vagy sem. Ezzel megszűnhetne az adatok dupla bufferezése is. Az IO rendszer mellett más, mind a DBMS-ben, mind az OS-ben előforduló egyéb területek is, mint pl. a védelem, vagy az osztott erőforrás-felhasználás, hasonló lehetőségeket adnak a DBMS további teljesítménynöveléséhez. A DBMS másik oldala az alkalmazói programok rétege. Természetesen nem minden program tud kommunikálni a DBMS-sel. Az alkalmazói programot fel kell készíteni az adatcserére. A kommunikáció ugyanis felügyelet alatt, megadott szabályok szerint megy végbe. Rendszerint mind a küldő, mind a fogadó oldalon létezik egy, a kommunikációra szolgáló komponens, az adatkommunikációs (DC) komponens, melyek megértik egymást, úgymond azonos nyelven beszélnek. Emellett szükség van még olyan komponensre is, mely a DBMS és az alkalmazói program között továbbítja az üzeneteket. Az üzenetküldés lehet egyszerű, ha például azonos processzen belül fut mindkét elem, de lehet összetettebb is, amikor a két oldal egy hálózat más-más csomópontján találhatók, tehát hálózati kommunikációs szoftver is szükség van. Ezen változó összetételű komponensekből felépülő, az alkalmazás és a DBMS között húzódó szoftver réteget szokás program interface-nek is nevezni. Abból a tényből, hogy a DBMS és az alkalmazói programok külön processzeket alkothatnak, következik, hogy egy általános DBS egy kliens- szerver architektúrájú rendszernek is tekinthető, hiszen van egy kliens oldal, az alkalmazói program, mely adatbáziskezelési igényekkel, utasításokkal lép fel az DBMS-sel szemben, amely az utasításokat, mint szerver végrehajtja. Ugyan a kliens és a szerver is elhelyezkedhet ugyanazon a gépen, de rendszerint amikor a kliens-szerver architektúrára gondolunk, sokunknak rögtön a hálózat jut eszünkbe, hiszen a klienst és a szervert a hálózat különböző csomópontjaihoz kötve szoktuk használni. Ennek az elrendezésnek is számos előnye van: - gyorsabb végrehajtás, több processzor dolgozik egyidejűleg - a szervert illeszteni lehet az adatbáziskezeléshez - a kliens gépet illeszteni lehet a felhasználói igényekhez - több kliens gép is csatlakozhat egy szerverhez - rugalmas kiépítés, fejlesztés Nézzük meg milyen globális folyamatok zajlanak le az adatbáziskezelő rendszeren belül. A DBMS egy sok-sok különböző egységből felépülő nagy gyárhoz hasonlítható, melyben az egységeknek összehangolt munkát kell végezniük, hogy biztosítsák a rendszer hatékony működését. A DBMS esetében a feladat összetettsége és bonyolultsága megköveteli, hogy részfeladatokat jelöljünk ki, s külön modulokat hozzunk létre az elkülöníthető tevékenységekhez. A már megismert funkcionális követelmények jó támpontot adnak a DBMS belső funkcionális felbontásához, csak néhány új fogalom szerepel majd a teljesebb leírás végett. A DBMS-ek legfontosabb komponenseinek vizsgálatánál a DBMS-t rendszerint két nagy struktúraegységre bontják, egy felhasználóhoz közeli rétegre (Data System), és egy a hardware-hez kapcsolódó rétegre (Storage System). Míg a Data System feladata az adatok adatmodell szerinti kezelése, a Storage System az adatok fizikai tárolási struktúrájával dolgozik. A DBMS-en belül a két réteg között intenzív kommunikáció folyik, mindkettő a felhasználó és az adatbázis közötti adatcsatorna szerves része. A Data System fogadja a felhasználó utasításait, majd értelmezi az utasítások végrehajthatóságát és meghatározza az utasításhoz tartozó fizikai műveletsort. Ez a műveletsor kerül át a Storage System-hez, amely saját IO rendszerében elvégzi a fizikai adatátviteli lépéseket, ügyelve a konkurens hozzáférésből és a védelmi szempontokból adódó feladatokra.

6. ábra Mindkét réteg tovább bontható funkcionális elemire. Elsőként vegyük a Data System legfontosabb komponenseit: - DC komponens, melyet már ismertettünk és melynek feladata az interface biztosítása a segédprogramok, a felhasználók felé - Utasításértelmező. E komponens feladata egyrészt az utasítások szintaktikai ellenőrzése, másrészt az utasítások tartalmi, végrehajthatósági vizsgálata. Ehhez az adott adatmodell, adatkezelő nyelv ismerete mellett szükség van a kezelt adatbázis adatbázismodelljének az ismeretére is. Itt most nem az adatok ismeretére gondolunk, hanem az adatstruktúrára illetve a védelmi és integritási feltételekre. Ezek az adatok pedig a már korábban említett metaadatok közé tartoznak. A DBMS az adatbázishoz tartozó metaadatokat az adatszótárban, Data Dictionary-ban tárolja. Az értelmezés feladatát, az eltérő jelleg miatt gyakran külön választják DDL és DML értelmezőkre. - Optimalizáló. Mivel a felhasználóktól összetett utasítások is érkezhetnek, és egyidejűleg több utasításcsoport is állhat végrehajtás alatt, nem lényegtelen az elemi utasítások végrehajtási sorrendje. Egy utasítás ugyanis rendszerint több elemi részlépésre bontható fel, több utasítás esetén a generált elemi utasítások végrehajtási sorrendje is tág határok között változhat, tehát egyazon feladatcsoporthoz több elemi utasítássorozat is tartozik, s ezen sorozatok mind helyigényben, mind gyorsaságban különbözhetnek egymástól. Emiatt a DBMS egyik lényeges feladata az optimális elemi utasítássorozat kiválasztása. - Végrehajtó. Az optimális elemi utasítássorozat végrehajtása történik ebben a modulban. Az utasítás-végrehajtás vezérlése mellett e komponens feladata az elemi utasítások végrehajtási kódjainak a tárolása, felhasználása is. Ebben a modulban is történik döntéshozatal, ugyan már sokkal szűkebb hatáskörben, mint az előző komponensnél, ugyanis bizonyos műveleteknél az algoritmusváltozat kiválasztása, csak az előző elemi lépés eredményének ismeretében történik meg. Az elemi utasítások végrehajtása során rekordszintű IO utasítások állnak elő, melyek feldolgozása már a Storage System feladata lesz. A Stotage System legfontosabb komponensei: - IO rendszer. Mint már említettük, a DBMS specifikus igényei miatt saját IO rendszert, bufferkezelést, helyfoglalási mechanizmust építenek be a legtöbb fejlettebb DBMS-be. Ez a rutinkönyvtár az OS IO kezelésénél magasabb szintű, a DBMS bufferhez kapcsolódó rutinokat tartalmaz. Ezek a rutinok már közvetlenül hívhatják az OS alacsony szintű IO rutinjait. - Konkurens hozzáférés vezérlés. Majd a későbbiekben látni fogjuk, hogy milyen eszközök állnak rendelkezésre a megosztott erőforrások kezelésére. E modul tartalmazza mindazon alacsony szintű adatstruktúrákon értelmezett módszereket, melyek az osztott hozzáférés vezérléséhez szükségesek. - Adatvédelmi rendszer. E modul feladata a különböző adatsérülések, rendszer leállások okozta veszteségek minimalizálása, az adatok megfelelő védelmének biztosítása. Ez a komponens is több olyan kisebb részből áll elő, mint pl. a rendszeres háttérmentés végzésére szolgáló rutin. Az előbbiekben felvázolt DBMS architektúrát összefoglalóan szemlélteti a következő ábra.
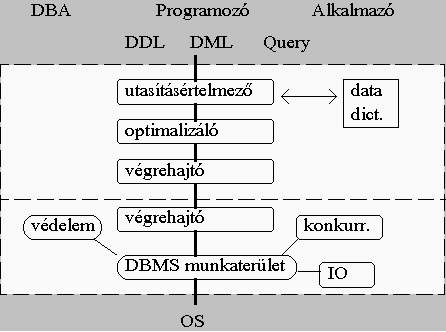
7. ábra A DBMS belső struktúrájával közvetlenül sem a felhasználó, sem az alkalmazás programozó nem fog találkozni, számukra rejtve maradnak a DBMS össz etettségének jelei. Ami egy felhasználót igazában érdekel, az a DBS felhasználói kapcsolattartása, azon segédprogramok rendszere, melyeken keresztül elérhetők az adatbázisban tárolt adatok. Az adatbáziskezelők segédprogramjai A DBMS fölött számtalan szoftvertermék foglal helyet, melyeket a felhasználói csoport alapján célszerű egymástól elkülöníteni, melyhez a felhasználók hármas tagolása ajánlott: - rendszermenedzser és operátor - alkalmazásfejlesztő és adatbázisfejlesztő programozók - felhasználók Az első csoport számára készültek azok segédprogramok, tools-ok, melyekkel az egész adatbázis működését érintő tevékenységek végezhetők el. Nézzük az ide sorolható legfontosabb programokat: - Adatbázis adminisztrátor monitor. Ezzel a segédprogrammal az adminisztrátori jogkörrel felruházott személy elvégezheti többek között az - az adatbázis indítását, leállítását - az adatbázis alapparamétereinek beállítását - az adatmentések elvégzését - DBMS hatékonyság és a felhasználói tevékenységek figyelését. - Loader. Külső szöveges vagy szekvenciális állományokban tárolt adatoknak az adatbázisba történő gyors betöltésére szolgál. Az adatátvitel során szűrőfeltételek adhatók meg és adatkonverziók is elvégezhetők. Az elvégzett műveletek naplózhatók is. Ezzel a segédprogram a különböző platformokon futó adatbázisok közötti adatcserére is jól használható. - Backup (Export, Import). Az adatbázis adatainak a lementésére és visszatöltésére szolgál. Bizonyos rendszereknél két külön program valósítja meg ezt a funkciót, az Export segédprogram végzi az adatok kimentését, míg az Import programmal lehet a lementett adatokat visszatölteni. A backup rendszer az adatok adathordozó sérüléséből vagy egyéb okokból eredő elvesztésének megelőzése mellett egyazon DBMS rendszer különböző verziószámú változatai közötti adatkonverzióhoz is felhasználható. A legtöbb DBMS-nél lehetőség van a szelektív mentésre, ahol a szelekció mind az adatok jellegére, mind az adatok aktualitására vonatkozhat. Ez utóbbi alatt azt értjük, hogy az adatbázisnak csak azon adatai kerülnek lementésre, melyek a legutolsó mentés óta módosultak, vagy azóta jöttek létre. A mentés során az adatbázis adatai bináris állományokba kerülnek le. A segédprogramok nagy része a következő csoportnak, az alkalmazás és adatbázis tervezőknek, fejlesztőknek készült. Az ide tartozó programok köre igen széles területet ölel fel, az interaktív eszközöktől kezdve a hagyományos programozási segédeszközökig. A szoftverfejlesztés rohamosan fejlődő területe egyre újabb módszereket, technikákat fejleszt ki, és az adatbázis- és alkalmazásfejlesztő rendszerek is követik és alkalmazzák ezen új eszközöket. Ez a gyors hatékonyságnövelő fejlődés magával hozza a fejlesztő rendszerek gyakori változását is, s a programozóknak is folyamatosan újabb és újabb paradigmákat, módszereket kell megtanulniuk. Habár a fejlesztő eszközök megjelenésükben, kezelésükben gyakran módosulnak, jellegük, céljuk azonos marad, s így behatárolható azon feladatok köre, melyek alapvető fontosságúak a fejlesztéshez. A legfontosabb segédeszközök: - Interaktív kezelő felület. Parancsorientált, vagy grafikus felületet biztosít a felhasználónak. A kiadott utasítások rögtön végrehajtásra kerülnek, s csak az eredmény kiírása után adható meg a következő utasítás. - Űrlapkészítő(Forms). Ez a modul nemcsak egy űrlap megtervezésére szolgál, hanem valójában egy alkalmazásgenerátort rejt magában, s mivel az adatbáziskezelő alkalmazások rendszerek űrlapokon keresztül jelenítik meg az adatokat, ezért nevezik ezt a komponenst űrlapkészítőnek is. A formai megjelenés mellett itt kell megadni az adatszerkezetet és a vezérlési algoritmust is. - Jelentéskészítő. Mivel az adatoknak a képernyőn, űrlapokban történő megjelenítése mellett, gyakran szükség van a nyomtatott listákra is, ezért külön komponens szolgál a nyomtatási listák gyors elkészítésére. Mind a jelentés, mind az űrlap formátumának meghatározásánál a fejlesztő rendszer felhasználja az adatbázisban tárolt metaadatokat is. - Menükészítő. Mivel egy összetett alkalmazás több elemi részfunkcióból épül fel, ahol az egyes részfunkciókhoz egy-egy űrlapot lehet megfeleltetni, ezért a részfunkciókat az áttekinthetőség és gyors elérhetőség végett menühierarchiába szervezik. A menükészítő alkalmazása esetén elegendő a menüszerkezet hierarchiáját egy egyszerű nyelvvel leírni, a hozzá tartozó kód ezután már automatikus generálódni fog. - Program interface. Mivel az űrlap és jelentéskészítő komponensek a tipikus alkalmazás felépítését követik, ezekhez igazítottak, ezért igen nehéz nem tipikus, speciális követelményekhez igazodó alkalmazások elkészítése ezen eszközökkel. A hagyományos programozási nyelvek sokkal nagyobb rugalmasságot biztosítanak ebben a tekintetben, ezek hátránya viszont, hogy a rendszerkönyvtáraik nem biztosítnak DBMS szintű adatkezelést. E probléma megoldására szolgálnak a DBMS-ek programinterface-i, melyek egy-egy programozási nyelvéhez tartozó függvény és eljáráskönyvtárban és előfordítókban testesülnek meg, és segítségükkel a normál programforrásszövegbe beszúrhatók a kapcsolódó DBMS adatkezelő utasításai is, tehát a programból elérhetővé válnak a DB-ben tárolt adatok is. - CASE eszközök. Az adatbázis megtervezéséhez nagyszámú feltételt és körülményt kell figyelembe venni. Az elemzés eredményét egy olyan adatmodellbe kell letárolni, mely közvetlenül felhasználható az adatbázis létrehozásához. A nagy adatmennyiség mellett, egy ebből fakadó másik problémát jelent, hogy a tervezés rendszerint nem egy ember munkája, hanem csapatmunka. Emiatt különös gondot kell fordítani a dokumentációk szabványosságára, a feladatok kiosztására. A CASE eszközök jelentős segítséget nyújtanak a tervezésben, a csoportmunka összehangolására. Legtöbb esetben a CASE komponens eredménye közvetlenül felhasználható az űrlapok és jelentések, menük generálásához. A felhasználók számára elkészült alkalmazói programok nagy része egyedi megrendelésre készült, az előbb említett fejlesztői eszközök segítségével. Vannak azonban olyan gyakrabban igényelt szolgáltatások, alkalmazások is, melyeket a szoftvergyártó cégek polcról levehetően árusítanak. Ezen cégekhez tartozik a DBMS gyártók mellett több független szoftverfejlesztő cég is. Mivel az alkalmazások elképesztően széles területet ölelnek át, a banki, gyártásirányítási rendszerektől kezdve a különböző szakértői rendszerekig terjedően. E terület teljes áttekintése helyett, mely helyigénye jóval meghaladná a rendelkezésre álló kereteket, ezért csak ízelítőt adunk e terület sokszínűségéről az egyik nagy DBMS gyártó cég, az Oracle ilyen irányú kínálatából merítve: - Dokumentum nyilvántartó rendszer. Különböző szöveges dokumentumokban letárolt információk karbantartására, visszakeresésére szolgál, ahol a keresést kulcsszavak megadásával lehet könnyíteni. A dokumentumok adatbázisokban és normál állományokban is tarthatók. A rendszer alkalmas a dokumentumok és a strukturált adatok kombinálására is, és a összekapcsolható a különböző fejlesztőrendszerekkel is. A program fejlettebb változataiban már hypertext és multimédia lehetőségek is beépítésre kerültek. - Office program. Ez egy hivatali, ügyviteli programcsomag, amely magában foglal többek között szövegszerkesztőt, levelezőrendszert, elektronikus naplót, egy kis személyi kalkulátort. A rendszer egy vállalat több egységét köti össze a helyi hálózaton keresztül. - Interaktív adatlekérdező. Programozói, adatbáziskezelői ismeretekkel nem rendelkező felhasználók részére biztosít, egy könnyen kezelhető felületet az adatbázis felé. Táblázatos formában, menü- vagy egérvezérelten kezelhető program, mellyel gyorsan végrehajthatók a lekérdezések, adatmódosításokat, adatfelviteleket. A rendszer egyszerűbb jelentések elkészítésére is alkalmas. - Adatvizualizáció. Ezen alkalmazással az adatbázisban letárolt adatok grafikus táblázatokban jeleníthetők meg, emellett lehetőség van képek, rajzok elkészítésére, letárolására is. A korszerűbb változatokkal már multimédia alkalmazások is futtathatók. A grafikus felület emellett monitor funkciókhoz kapcsolhatók, azaz, grafikusan is nyomonkövethetők az adatok értékeinek változása. - Vállalati nyilvántartó rendszer. A termék több, önállóan is használható részfunkciót foglal magába, melyek közül a legismertebbek a számlázó rendszer, a könyvelési rendszer, a pénzügyi és személyzeti rendszer, a rendelések és a raktárak nyilvántartása. - Termelés tervező rendszer. A rendszer az erőforrások és kapacitások nyilvántartása mellett az erőforrások kiosztásának megtervezésére is lehetőséget ad. A várható piaci igények elemzésével meghatározható a termelés ütemezése. - Gyártás ütemező és vezérlő rendszer. A költségtényezők és a technológiai megkötöttségek, kiválasztott ütemezési módszer alapján optimalizálható a gyártás, s felmérhetők a gyártási rendszer esetleges gyenge pontjai is. - Vezetői információs rendszerek. A vállalat felsőszintű vezetése számára biztosítja a szükséges összesített adatokat, lehetőséget adva bizonyos statisztikai kiértékelésekre. A rendszer felhasználható döntéshozatali segédeszközként is. A felsorolást még sokáig lehetne folytatni további alkalmazási területekkel, de talán már ebből is érzékelhető, hogy az adatbázisok alkalmazásának fő területeivé a vállalati nyilvántartási és termelésirányítási rendszerek, valamint az államigazgatási nyilvántartó rendszerek váltak. Az említett alkalamazásokban a DBMS központi szerepet tölt be, hiszen az összes többi komponens ráépül a DBMS-re, tehát az alkalmazásokban is a DBMS lehetőségei és jellege tükröződnek vissza. Így nemcsak az adatbázis menedzsernek, hanem az alkalmazásfejlesztő programozóknak is ismerniük kell a DBMS lehetőségeit és kezelő felületét. Mint már említettük, az idők folyamán több különböző DBMS-t fejlesztettek, nagyobb részük részleteiben kidolgozottan kutatási célból jöttek létre, de ma már számtalan DBMS a piacon is kapható. Nemárt, ha el tudunk igazodni a DBMS-ek sokszínű világában, tudjuk hogyan lehet a DBMS segítségével az adatbázishoz hozzáférni, ezért a következő fejezetben a DBMS-ek viselkedésével foglalkozunk, és bemutatjuk a külvilág, az alkalmazások felé nyíló megjelenését. Az adatbáziskezelő rendszerek osztályozása A DBMS-ek most megadandó osztályozása nem a belső felépítésen, hanem a DBMS-nek a fejlesztő, a felhasználó felé mutatott képén alapszik, melyhez az alábbi szempontok köthető: - adatmodell - felhasználók száma - DBMS csomópontok száma - támogatott hardware és OS típusok A kezelő nyelvet, a DBMS viselkedését tekintve a legalapvetőbb kritérium a DBMS-hez tartozó adatmodell, de ennek ismertetése előtt a többi, gyorsabban áttekinthető szempontot tekintjük át. A felhasználók száma alapján, hasonlóan az operációs rendszerekhez, megkülönböztetünk egyfelhasználós és többfelhasználós rendszereket. Ugyan korábban azt említettük, hogy az adatbáziskezelést elsődlegesen a többfelhasználós környezetre tervezték, de a hatékonyabb adatkezelés, az egyszerűség, olcsóság miatt, esetleg betanulási céllal sokan vásárolnak egyfelhasználós rendszereket is, melyek szinte kivétel nélkül az egyfelhasználós operációs rendszereken, pl. az MSDOS, Windows alatt futnak. A DBMS csomópontok száma alapján beszélhetünk egyedi DBMS-ről, amikor csak egy gépen fut a DBMS, és osztott DBMS-ről, amikor több csomóponton is fut egyidejűleg a DBMS. A támogatott hardware és OS megadása a felhasználó számára a termék kiválasztásakor válik fontossá, hiszen a meglévő és tervezett hardware és OS feltételek behatárolják a választási lehetőségeket. Az adatmodell, mint már említettük az adatok logikai tárolási formátumát határozza meg, egy olyan vázat ad meg, melybe az adatok majd beletölthetők lesznek. Az adatmodell megadása eszerint egy szerkezetleírást jelent, hasonlóan egy normál program struktúra deklarációjához. Ezt az elképzelést azonban meg kell még toldani annyival, hogy az adatrendszer ismerete nem csak az adatszerkezet ismeretét, hanem az adatok kezelési módjának az ismeretét is magában foglalja. Ezért az adatmodellbe a statikus szerkezet leírás mellett a dinamikus, az adatokon értelmezett műveleteket is beleértik. Az adatmodell megadásánál mind a szerkezet, mind a műveletek megadása logikai szinten, s nem fizikai szinten történik, ezért az adatmodell egy elvontabb absztraktabb, formálisabb leírást jelent. Összegezve tehát az adatmodell egy olyan matematikai formalizmus, mely az adatok és az adatokon értelmezett műveletek leírására szolgál. Az egyes adatmodellek a kiválasztott formalizmus jellegében különböznek egymástól, a deduktív adatbázisok például logikai formalizmust használnak fel. Ugyan több adatmodell is létezik, de ezekből négy terjedt el igazán a gyakorlati életben: a hierarchikus, a hálós, a relációs és az objektum orientált adatmodellek. Ezek közül a relációs adatmodell a legnépszerűbb ma, a hálós modell kezd háttérbe szorulni, míg a hierarchikus már inkább a múlté, míg az objektum orientált modell a jövőben válik csak igazán piacéretté. A hierarchikus adatmodell az adatokat egy hierarchikus faszerkezetben tárolja. E fa mindegyik csomópontja egy rekordtípusnak felel meg. A hierarchikus modell alapja, hogy a gyakorlati életben a szervezetek vagy éppen a struktúrák nagyon gyakran hierarchikus felépítésűek, gondoljunk csak a vállalati hierarchiára vagy egy gyártmány alkatrészeinek hierarchiájára. Emiatt természetesnek tűnik, hogy a modellezés megkönnyítésére a valóságban leggyakrabban használt, hierarchikus modellt hozzuk létre. Ez a modell a gyakorlati alkalmazások során fejlődött ki , ezért nincs olyan elméleti megalapozottsága mint a későbbi adatmodelleknek. A modellhez kapcsolódó DML nyelvek mind rekordorientált adatmegközelítést alkalmaztak. A bonyolultabb kapcsolatok ábrázolása csak kerülőutakon lehetséges. A modell előnye, hogy a hierarchikus szerkezet egyszerűen leírható és tárolása a mágnesszalagos tárolási formához is jól illeszkedik. A hálós adatmodell a hierarchikus modell továbbfejlesztése, mely jobban illeszkedik a bonyolultabb kapcsolatok ábrázolásához is. Ebben a modellben az egyedek között tetszőleges kapcsolatrendszer, egy kapcsolatháló alakítható ki. Az adatszerkezet leírása, mivel a háló tetszőleges nagy lehet, nem egy adategységgel, hanem több kisebb, hierarchikus felépítésű adategységgel történik. Ehhez a modellhez is rekordorientált adatmegközelítést alkalmaztak a DML kialakításakor. A hálós modellen alapuló DBMS igen elterjedtek a nagygépes környezetben, hiszen a hálós modell nagy adatmennyiségek viszonylag gyors feldolgozását teszi lehetővé. A kezelőnyelv bonyolultsága, viszonylag merevebb szerkezete gátolta szélesebb körben történő elterjedését. A relációs adatmodell sokkal rugalmasabb szerkezet biztosít az elődeihez viszonyítva. Az adatbázis azonos rekordtípusokat tartalmazó táblákból épül fel, ahol minden tábla teljesen egyenértékű, s nincs semmilyen az adatdefiníciókor véglegesen lerögzített kapcsolat, váz, mint ami az előző modelleknél előfordult. A relációs modellben az egyedek közötti kapcsolatok az adatértékeken keresztül valósulnak meg. A relációs modellben a táblákon értelmezett műveletek ugyan halmazorientáltak, de számos olyan implementáció létezik, melyben rekordorientált műveletek használhatók. A modell elterjedése az egyszerűségének és rugalmasságának köszönhető. Az objektum orientált modell célja az objektumorientáltság szemléletmódjának alkalmazásával minél valósághűbb adatmodellt megalkotása. Az egyedek ugyanis sokkal szemléletesebben írhatók le az objektumokkal, mint a relációs modellben szereplő rekordokkal. Az objektum orientáltság a megvalósult rendszerekben lehet teljes vagy részleges. A részleges OODBMS-ek rendszerint csak strukturálisan objektum objektum orientáltak, a funkcionális, aktív elemek csak a teljes OODBMS-ekben jelennek meg. Az OODBMS-ek elterjedését az egységes elméleti alapok hiánya és az implementációs nehézségek fékezik. Az egyes adatmodellek ismertetéséhez, bővebb leírásához szükség van bizonyos adatmodellezési alapfogalmak megismerésére, melyek szorosan kötődnek az adatbázisrendszerek tervezésének módszertanához, ezért a fenti modellek teljesebb bemutatására a későbbi fejezetekben fog sorra kerülni. Az adatbázisrendszerek tervezési lépései Az adatbázisrendszerek tervezésének vizsgálatakor abból a tényből kell kiindulni, hogy a DBS is egy számítógépen futó program, egy software termék, ezért az általános szoftverfejlesztési irányelvek itt is érvényesek. A szofverfejlesztés (SE Software Engineering) általános metodikája mellett természetesen a DBS-ek specifikumait is figyelembe kell venni. Az SE folyamatának egyik szemléletes megjelenítője az SE piramis, melyben
8. ábra A piramis a következő lépéseket foglalja magába: - követelmény analízis: a vizsgált problématerület elemzése, a a megoldandó feladatok, a követelmények meghatározása - rendszerelemzés: a problématerület modellezése, a belső struktúrák és működés feltárása több különböző szemszögből és különböző részletességgel - rendszertervezés: az elkészítendő szoftver belső struktúrájának, működésének több különböző szemszögből történő feltárása, különböző részletesség mellett - kódolás: az elkészült modell leírás átkonvertálása a számítógép által érthető formára, valamely programozási nyelvet felhasználva - tesztelés: az elkészült kód hibamentességének ellenőrzése - karbantartás: folyamatos ellenőrzés, módosítások, hibakijavítások sorozata Természetesen itt nem szabad elfelejteni, hogy a tervezés folyamata nem egy egyszerű szekvencia, mivel bizonyos elemek többször is megismétlődnek, s a tervezés egy ciklikus folyamattá alakul át, s a fenti felsorolás ennek a ciklusnak az elemeit sorolja fel egy kvázi, logikai sorrendben. Ha az egyes tevékenységek absztrakciós szintjeit vizsgáljuk, akkor látható, a piramisban fentről lefelé haladva egyre csökken a leírásmód elvontsága és egyre nagyobb szerepet kap a konkrétabb megfogalmazás. A szoftvertermék leírása a fejlesztés során fokozatosan alakul át az absztrakt, esetleg pármondatos köznapi leírásból a futtatható többezer soros gépi kódsorozatig. Ez az átalakulás a modellek sorozatán keresztül valósul meg. Előbb absztraktabb, majd később konkrétabb, részletekkel gazdagított modellek jelennek meg. A DBS rendszer sem tér el ettől fejlesztési metodikától, sajátossága, egyedisége leginkább a felhasznált modellekben rejlik. A DBS rendszerek jellegzetessége, hogy kiemelt helyen, elsődlegesen az adatrendszerre koncentrál. Különösen fontos tevékenység az adatbázis megtervezése, hiszen a DBS központjában a DB áll, s ennek hatékonysága, korrektsége az összes alkalmazás teljesítményére kihat. Az adatbázis tervezése kettős célt követ, egyrészt ki kell elégíteni a felhasználók információ-igényét, az információkat könnyen kezelhető struktúrába kell elhelyezni. Másrészt ügyelni kell az információfeldolgozás igényeire is, melyek többek között a végrehajtás sebességét, a helyigényt érintik. A DB tervezésékor is több modellen keresztül jutunk el a fizikai adatbázishoz, hiszen induláskor rendszereint csak igen informális ismereteink vannak a feladatról, a modellezett világról. Ezzel szemben az elkészített adatbázisrendszer egy igen szigorú, formális nyelvvel írható le. Több modell létezik, melyek különböző absztrakciós szinteken írják le a megvalósítandó adatbázist. Mivel ezek mindegyike az adatbázis leírására szolgál, mindegyikre használható az adatmodell kifejezés. Az adatmodelleket alapvetően két nagy csoportba szokás osztályozni, az egyik adatmodelltipus a szemantikai adatmodell (SDM) vagy koncepcionális (concepual) adatmodell, mely elvontabb szinten, részletek nélkül, emberközelien írja le az adatszerkezetet. Az SDM-ek alkalmasak az adatbázis lényegének a kiemelésére, a szerkezet megértésére. Egy adott adatbázis SDM ugyanaz marad akkor is, ha esetleg módosul a kiválasztott DBMS, hiszen a modellezett valóság is változatlan marad, s az SDM valóságközeli modell- leírás. A másik csoport a konkrétabb, DBMS közeli adatmodellek köre, melyekből már megemlítettük a relációs, hálós, hierarchikus és OO modelleket. Ezek a modellek a rugalmasságaik ellenére mégiscsak egyfajta korlátozást, keretet szabnak, melybe bele kell gyömöszölni a valóságot. A valóság tökéletes leírásához azonban a meglévőnél sokkal gazdagabb lehetőségekre lenne szükség, mint amit a hagyományos DBMS adatmodellek támogatnak. Mivel ezek a modellek túlságosan távol vannak a modellezett valóság közvetlen leírásától, ezért rendszerint felhasználják a szemantikai adatmodelleket is a tervezésnél, első lépcsőként, s az elkészült SDM-et konvertálják át DBMS adatmodellre. A modellek szerepének kiemelésével újrafogalmazhatjuk az adatbázis tervezésének főbb lépéseit: - Igényfelmérés és analízis - Koncepcionális adatbázismodell elkészítése - DBMS rendszer kiválasztása - A fogalmi modell átkonvertálása adatbázis adatmodellre - A fizikai adatmodell tervezése - Adatbázis implementálás Az egyes tervezési lépések módszereinek és eszközeinek részletes tárgyalására egy későbbi fejezet keretében fog sorkerülni.