
A relációs adatmodell
A relációs adatmodell kialakulása
A relációs adatmodell napjaink legelterjedtebb adatmodellje. A modell alapjait 1970-ben fektette le Codd az "A Relational Model of Data for Large Shared Data Banks" cikkében. A cikk elsôdleges célja volt, hogy bebizonyítsa, hogy létezik más alternatíva is az akkor elterjedõ hálós adatmodell mellett, mely ráadásul matematikailag megalapozott eszközöket, fogalmakat használ, így pontosabb, egzaktabb leírást, kezelést tesz lehetôvé.
A megtervezett modellben olyan egyszerû, könnyen megtanulható leírási módot sikerült megvalósítani. Egyszerûségének következtében gyorsan népszerûvé is vált a felhasználók körében, s sok implementációja született meg a személyi számítógépek piacán is. Az elméleti megalapozottság másrészrôl a kutatók, a szakemberek szimpátiáját is kiváltotta, s ez a modell számos új fejlesztési projekt alapját képezi. Az adatmodell mindenki számára fontos elônye az egyszerûség mellett a modell rugalmassága.
Az eddigiekben már ismertetett speciális modellezési problémák, mint az N:M kapcsolatok, az integritási feltételek itt viszonylag természetes, nem kilógó módon valósíthatók meg. Természetesen ezen modellnek is vannak gyengeségei, melyek elsôsorban a különbözô szemantikai modellelemek hiányában rejlik, ezért is folynak oly intenzív vizsgálatok a relációs modellnek újabb, SDM modellekhez közelebb álló komponensekkel történô kibôvítésére.
A relációs modellt megalkotó Codd az IBM cégnél dolgozott, s abban az idõben az IBM igen sok energiát ölt már bele a hálós adatmodellen alapuló DBMS rendszerének kialakítására. Mint vezetõ adatbázistechnológiai cég, az IBM nem engedhette meg, hogy ne vegye figyelembe ezt az újszerû ötletet, ezért beindított egy kisérlety projektet, amelynek célja a relációs modell megvalósíthatóságának a vizsgálata, egy minta relációs DBMS (RDBMS) volt. A beindított projekt a System/R elnevezést kapta, ahol az R betû a relációs (relational) jelölésre utal.
A System/R projektet két fázisban zajott le. Az 1970-es évek közepére kifejlesztettek egy prototipus RDBMS-t, amely még egyfelhasználós környezetben mûködött. Az elsõ részben a kutatás a fizikai elérési módszerek kidolgozására, a kezelõ nyelv kialakítására, és a mûveletek optimalizálására irányultak. A projekt második fázisában kibõvítették a rendszert többfelhasználós plattformra, így már egy igazi, gyakorlatban is alkalmazható RDBMS rendszert hoztak létre. A projekt 1976-ban zárult le, bizonyítja a relációs modell életképességét.
A System/R sikereire felfigyeltek más szoftverfejlesztõk is. Ennek következtében a 70-es évek végére kialakult néhány új önnálló társaság, amelyek a piacon is eladható RDBMS rendszerek kifejlesztésébe kezdtek bele.
Az elsõ termékként megjelenõ RDBMS rendszer 1979-ben jelent meg. Ez egy PDP-n futó Oracle rendszer volt. Talán sokunknak ismerõsen cseng ez a név, hiszen az Oracle ma is a világ legnagyobb RDBMS forgalmazó cége, melynek nyeresége napjainkban is drasztikusan fokozódik. Az Oracle rendszer mellett, más cégek is jelentkeztek nemsokára saját RDBMS termékeikkel, e RDBMS nevek között megemlíthetõk az Informix, Ingres, DB2, Sysbase ésRDB.
A relációs modell sikerén és egyszerûségén felbuzdulva a PC-s rendszerek elterjedésével olyan cégek is felbukkantak, akik a relációs modellen alapuló PC-s adatkezelõ rendszereket jelentettek meg. Ugyan e rendszereket a szolgáltatásaik, képességeik és megbízhatóságuk miatt sokan nem tekintik igazi RDBMS rendszereknek, de struktúrális alapjaikban a relációs adatmodellhez állnak a legközelebb és najainkban e rendszerek egyre több elemet meg is valósítanak a relációs adatmodellbõl. A piacon e rendszerek igen jelentõs szerepet töltenek be, hiszen megfizethetõek és kisebb alkalmazások részére megfelõ szolgáltatást nyíjtanak. Ezért mi is nagyobb teret fogunk szentelni e PC-s rendszerekre is.
A relációs modell, mint minden más adatmodell tartalmaz statikus és dinamikus elemeket is. A statikus elemek az adatok tárolási struktúráját írják le, míg a dinamikus oldal a struktúrákon végzendô operációkat, mûveleteket adja meg. A relációs modell a struktúra és a mûveletek mellett megjelentet egy újabb szempontot is, az adatintegritási komponenst, mely nem része sem a strukturális, sem a mûveleti komponensnek, hiszen elsôdlegesen az adatok értékét jellemzi, szabályozza. Az integritási feltételek tehát az adatok értékei közötti kapcsolatokat szabályozzák. Így a relációs adatmodell az alábbi három komponens együttesét jelenti:
- adatstruktúra
- mûveletek
- integritási feltételek
A relációs modell elõnyeit, fõbb jelemzõi tömören és leegyszewrûsítve a következõ pontokban foglalhatók össze:
- Az adatmodell egy egyszerû és könnyen megérthetõ struktúrális részt tartalmaz. A struktúrális rész egyszerûsége a közérthetõség mellett az alkalmazhatóságot is növeli, hiszen az egyszerûbb formulák általánosabban fordulnak elõ a különbözõ adatforrásokban. A relációs modell struktúrális része nem tartalmaz a fizikai szinthez közel álló részleteket, célja olyan adatstruktúra modell megalkotása volt, amely nagymértékben független a fizikai megvalósítástól, egyszerû és könnyen érthetõ.
- A modellhez olyan mûveleti rész csatlakozik, amely a programozási nyelveknél egyszerûbb kezelõi felületet biztosít, hogy minnél általánosabban, minnél szélesebb körben lehessen használni. Az utasítások a procedurális jelleg ehleyett deklaratív elemeket taralmaznak, azaz magasabb szinten lehet megfogalmazni a megkívánt tevékenységet. Az alkalmazott nyelv egyik jellegzetessége, hogy nem rekordonként kezeli az adatokat, hanem egyszerre több rekord együttesét is érinti. A deklaratív jelleg ellenére a kezelõ nyelv biztosítani tudja az adatkezeléshez szükséges minden mûveleti elemet.
- Az adatmodell integritási részében egyszerû, közérthetõ de egyben hatékony feltételeket definiál. Az integritási feltételek elõnye, hogy deklaratív megadásukkal a szabályok magában az adatbázisban kerülnek letárolásra, s az RDBMS automatikusan ellenõrizni fogja e szabályok betartását, pontosabban csak olyan tevékenységeket fog megengedni az RDBMS, amelyek nem sértik a megadott integritási elõírásokat.
- Egyszerû tervezési metodika, az adatbázis tervezése jól definált, egyértelmû elméleti alapokon nyugszik. A tervezés elméleti alapjai az úgynevezett normalizálási szabályokon alapulnak, amely a relációs modell struktúrális lehetõségeit és a modellezendõ fogalmak közötti függõségi kapcsolatokat veszi figyelembe. A normalizáció végigkövetésével egy hatékony, árttekinthetõ adatmodellt kaphatunk.
- Nagyfokú logikai függetlenség. A relációs modell elrejti a felhasználók elõl a megvalósítás részleteit. A felhasználó nyugodtan használhatja a magas szinten, hozzá közel álló fogalmakat, a rendszer egy belsõ optimalizáló komponens segítségével ki fogja választani a számára leghatékonyabb fizikai megvalóûsítást. A függetlensáég fokozására a rendszer lehetõvé teszi a különbözõ logikai nézetek definiálását, azaz egy létrehozott struktárát számos különbözõ nézetben is fel lehet használni.
- A relációs modell tiszta elméleti alapokon nyugszik. A halmazelméletre és a matematikai logikára alapozva a relációs modell az elsõ mélyebb elméletre támaszkodó adatmodell. Az elméleti megalapozottság fõ elõnye, hogy általa a modell megbízhatóbb és kiszámíthatóbb lesz, s könnyebb a modell tuléajdonságainak a vizsgálata is. A megbízhatóság biztosítja, hogy nem fogják kellemetlen események, váratlan hibák megzavarani az adatmodellen alapuló adatbáziskezelõk mûködését.
- Egységesség. Az adatbázisban mind a normál, mind az struktúra leíró, azaz metadaatok uigyanazon módon és formalizmussal kerülnek letárolásra, ezenklívül e adatok kezelése is ugyanazon utasításokkal valósítható meg. Ez nagyban megkönnyíti az adatbázis adminisztrációját is.
Az adatmodell három oldal közül elsôként a strukturális részt, majd az adatintegritási részt, legvégül a mûveletei részt fogjuk elemezni az elkövetkezõ fejezetekben.
Relációs adatstruktúra
A relációs adatmodell egyik fõ eltérése az eddigiekben vett hierarchikus modellhez viszonyítva abban rejlik, hogy nem épít be a modellbe fix, rögzített kapcsolattípusokat, mint a PCR vagy a VPCR volt. Valójában semmilyen elõzõ értelmezésen vett direkt kapcsolatleíró szerkezeti elem nem létezik a relációs modellhez ami nem jelenti azt, hogy a kapcsolatokat egyáltalán nem lehet letárolni. Ha ez igaz lenne, akkor természetesen nem használná senki a relációs modellt, hiszen a kapcsolatok nélküli modell a igencsak csonka képét adná a valóságnak. A relációs adatmodell a következõ strukturális elemekbôl épül fel:
- mezõk
- rekordok
- relációk
- adatbázis
Ezek a strukturális elemek egyre bõvülõ szinteket jelentenek, a rekord ugyanis több mezõbõl épülhet fel, a reláció több rekordot tartalmaz, az adatbázisba pedig több reláció tartozhat.
A relációs értelmezésben a mezõ egy tulajdonságnak felel meg. A mezõtípust a relációs terminológiában szokás domain-nek is nevezni. A domain alatt tehát a mezõ által felvehetõ értékek halmazát értjük. Egy életkor mezõ esetén, a mezõhöz tartozó domain a lehetséges életkorokat jelentõ egész számok halmaza lesz, például a [0-130] intervallum. Bizonyos értelmezésekben a domain-hez még egy értelmezési, jelentéselemet is hozzácsatolnak az értékhalmaz mellett. A domain jelentése az azonosító nevében testesül meg. Ez alapján, az életkor és a testsúly domain-eknek hiába is lenne azonos az értelmezési tartományuk, értelmük más és más, ezért nem szerepelhetnek együtt bizonyos operátorok esetén. Így például értelmetlen dolognak tûnik egy életkor és egy testsúly érték összeadása.
A relációs modellben, hadonlóan a hierarchikus modellhez, nem lehet sem összetett mezõket, sem többértékû mezõket definiálni. Ezek a megkötések a relációs modell azon alapelemei közé tartoznak, melyek nagymértékben növelték a megvalósíthatóság hatékonyságát, a modell egyszerûségét, de napjainkra, a bonyolultabb objektumok tárolásái igényeinek növekedtével, e megkötések egyben korlátaivá is váltak az adatmodellnek.
A domain tehát a relációs modellben elemi típusok halmazát jelenti. Az atomiság arra utal, hogy tovább nem bontható az adat. Igy domain lehet pl. a rendszámok halmaza, az életkorok halmaza. A domainek lehetnek standardok, kész domainek, mint pl. az egész számok halmaza vagy a sztringek halmaza, de a relációs modell lehetõséget nyújt saját domainek definiálására is.
A saját domain jelölés, pl. a rendszámok halmaza, több szemantikai értéket hordoz, szemléletesebb, és implicite más értékhalmazt is definiálnak mint a standard típusok. A domain megadásához meg kell adni egy domain nevet és egy adattípust, esetleg az adatformátumot is. Az adott típus hivatkozhat más, már ismert típusokra, azok leszûkítéseire.
A mezõket nevükkel és a hozzájuk rendelt domain megadásával azonosíthatjuk. Egy autó egyednél, például a rendszám tulajdonsághoz rendelhetjük a rendszám azonosítójú mezõt, melyhez a magyar viszonyoknál maradva egy magyar-rendszámok domain tartozhat. E domain adattípusa a hatkarakteres sztringek halmaza lehet, melyben az elsõ három karakter betû, az utolsó három pedig számjegy, azaz a formátuma "XXX999" alakú lesz.
A sémában több mezõ is szerepelhet ugyanazzal a domainnal együtt. Ennek elõnye, hogy jobban érzékelhetõ a mezõk közötti kapcsolatok, másrészt hatékonyabbá teszi a karbantartást is, hiszen ekkor több mezõ helyett csak egyetlen egy domian-nél kell az esetleges változtatásokat (pl. rendszám alakjának megváltoztatása) átvezetni.
A domainek jelentôs szerepet játszanak az adatmodell szemantikai értelmezésében,hiszen a domain neveket a szemantikai tartalom figyelembe vételével hoztuk létre. Ha részletsebben elemezzük a szemantikai tartalomjelentôségét, akkor arra a következtetésre juthatunk, hogy a szemantikai tartalom felhasználható lenne az adatmodell mûveleti, operációs részében is. Hiszen például összehasonlítani, netán összeadni csak azonos értelemmel bíró mennyiségeket szabadna. E megkötést a modellünk úgy támogathatná, hogy nem engedi meg csak az azonos domainhez tartozó mezôk közötti összehasonlításokat, vagy összeadásokat.
Másrészrôl a domainek létezése felhasználható lenne a domain orientált mûveletek elvégzésére is. Ez alatt azt értjük, hogy kiadhatnánk a rendszernek csak domain hivatkozásokat tartalmazó utasításokat is, mint pl. hogy az összes hosszúság adatot az adatbázisban szorozza meg 1.45-el, mert mértékegységváltás történt. A fenti szemantikai jellegû igények megvalósításával a legtöbb rendszer igencsak adós marad, így a domain-ek elsôdleges szerepe ma még nagyrészt a szemléletesebb sémaleírásra korlátozódik.
A rekord egy összetartozó mezôcsoportot definiál. A rekord elsô közelítésben megfeleltethetô az E/R modellbeli egyedeknek. Késôbb majd látjuk, hogy bizonyos esetekben, az adatbázis hatékonysága, integritás ôrzése érdekében célszerû eltérni ettôl az elvtôl, s egy rekord nem feltétlenül fog egy egyedtípust reprezentálni. A rekordtípust a nevével és a hozzátartozó mezôk megadaásával azonosíthatjuk. A mezôk megadásánál megemlíthetô, hogy a modell egyes formálisabb változataiban a rekordtípus a mezô típusok halmazát, míg más, gyakorlatiasabb változataikban a mezôtípusok listáját jelenti. E kétfajta megközelítés alapvetô különbsége, hogy egyikben sorrendiség áll fenn, míg a másikban, a halmazorientált leírásnál nincs semmiféle sorrendiség értelmezve a mezôk között.
A halmazorientált módnál a mezõ nevével kell hivatkozni a mezõre míg a listás megadásnál elegendõ a sorszámot felhasználni. Egy rekord elõfordulás esetén a kétféle megközelítési, megadási mód az alábbiakban szemléltethetõ:
A relációs adatmodell központi legsajátosabb eleme reláció. A reláció nem más mint az azonos típusú rekord elõfordulások összessége. A formálisabb megközelítésben, az igazi relációs adatmodellben ez az összesség halmazt jelent, vagyis a reláció az azonos típusú rekord elõfordulások halmaza, s ilyenkor nem tehetünk különbséget a rekord elõfordulások között a reláción belüli pozíció alapján, hiszen nem is értelmezhetõ pozíció a halmazelemek között.
Egyes megvalósított adatbázis-kezelõ rendszerek viszont listaként értelmezik a relációt, tehát feltételeznek valamilyen sorrendiségeket a rekord-elõfordulások között. Ennek a szemléletesebb leírásnak köszönhetõen a relációt egy táblázattal szokás reprezentálni. A halmazorientált szemlélet egy elvontabb, absztraktabb, logikai megközelítést tükröz, mely tudatosan szakít a fizikai nézettel. Hiszen tudjuk, hogy számítógépeinkben az adatok tárolása rendezetten történik, az adatot megint a címe azonosít, tehát a pozíció fizikailag elválaszthatatlan az adattól. A logikai és fizikai nézet különbségét emeli ki a halmazokra alapuló megközelítés.
A relációban szereplõ egyed elõfordulásokat a szakirodalomban tuple-ként
nevezik, mi magyarul a sor vagy rekord kifejezést fogjuk használni. . A relációra pedig alkalmazható a tábla kifejezést is. A következõ példa egy, az autók adatait tartalmazó relációt mutat be:

A példában a reláció azonosító neve AUTÓK. E tábla célja a modellezett problémakörben elõforduló autók adatainak a tárolása. Minden autóról a rendszám, tipus, kor és ár adatokat tartja nyilván. Az egyes mezõk karakter és numerikus értekeket vehetnek fel. A mezõk és a domain-jeik együttesen megadják a reláció struktúráját. Tehát az AUTÓK reláció struktúrája a következõ:
(rendszám char(6), tipus char(20), kor number, ár number)
A sorok a rekord elõfordulásokat, az oszlopol a mezõket, a tulajdonságokat reprezentálják. A tábla, reláció szerkezetét egyértelmûen meghatározza a benne foglalt rekordtípus, hiszen egy reláció csak egy rekordtípusbeli elõfordulásokat tárolhat.
A relációban tárolt rekord-elõfordulások száma viszont tetszõlegesen sok lehet. Mivel a rekordtípus és a reláció nagyon szorosan, szinte elválaszthatatlanul összefonódik, ezért a relációs modellben rendszerint nem is említenek külön rekordtípust, így csak a következõ szerkezeti elemeket definiálják. A relációtípus, a reláció séma megadása a reláció nevével és a mezõk felsorolásával történik meg.
A relációt a relációs modell kereteiben rekordelôfordulások halmazaként értelmezzük, s a halmazjelleg erôsítésére röviden összefoglaljuk az elméleti relációk tulajdonságait:
- a relációban ugyanaz a rekordelôfordulás nem fodrulhat elô többször. Egy halmaz egy elemét ugyanis csak egyszer tartalmazhatja, s ha két rekord minden mezôje megegyezik egymással, akkor a két rekord ugyanazt az elôfordulást jelenti, tehát csak egyszer fordulhat elô.
- minden mezô atomi értéket tartalmaz.
- a reláció elemei között semmiféle rendezettség, sorrend nem értelmezett (gyakorlatban nem mindig teljesül)
- a mezôk között semmiféle rendezettség, sorrend nem értelmezett (gyakorlatban nem mindig teljesül)
A reláció szó eredetileg kapcsolatot jelent, s a matematikában a reláció alatt több alaphalmaz Descartes szorzatának egy részhalmazát értik. Az elnevezés ezen adatmodellben történô használatának jogosságának belátására gondoljunk arra, hogy minden tábla a hozzá tartozó rekordtípus elméletileg lehetséges elôfordulásainak egy részhalmazát tartalmazza, ahol minden rekordelôfordulás a mezôkhöz tartozó domain halmazokból tartalmaz egy-egy elemet az egyes mezôiben, így egy rekordelôfordulás nem más, mint a domain halmazok Descartes szorzatának egy eleme. Így maga a tábla, vagy reláció nem más, mint a domain halmazok Descartes szorzatának egy részhalmaza, tehát a tábla, a reláció matematikai értelemben is megfelel a reláció definíciójának.

A relációk minôségi jellemzésére a reláció szerkezetét adjuk meg. A relációséma önmagában viszont csak egy üres váz, mely akkor nyer értelmet, ha feltöltôdik adatokkal. A relációkat ekkor már mennyiségi oldalukról is vizsgálhatjuk. A reláció fokszáma alatt a relációsémához tartozó mezôk darabszámát értik, míg a relációhoz tartozó rekordok darabszáma a reláció számosságát adja meg.
A relációk azonban nemcsak szerkezetükben és elôfordulásaik méretében különböznek egymástól, hanem létezésük módjában is. Vannak ugyanis olyan relációk, melyek elôfordulása és sémája az adatbázisban rögzítve vannak. Ezek a relációk a bázis relációk. A bázis relációk sémaleírása rögzített az adatbázis metaadatai között, illetve az elôfordulásának adatai a fizikai adatbázisban is letárolásra kerül. Mint majd látni fogjuk a relációs modellben értelemzett mûveletek relációkon értelmezettek és egy újabb relációt adnak eredményül. Az eredményreláció viszont rendszerint nem része az induló adatmodellnek, hiszen csak idôlegesen van rá szükség, illetve letárolása felesleges is, hiszen a benne tárolt adatok más relációkban megtalálhatók. Ezért ezen keletkezetett eredményrelációkat ideiglenes eredmény relációknak nevezik. Ha magát az elôfordulást is megôrizzük, akkor a leszármaztatott relációt snapshot-nak nevezik. A snapshot rendszerint csak olvasható, tehát nem módosítható relációt jelent, s elô lehet írni, hogy tartalma milyen idôközönként aktualizálódjon, ahol ez az aktualizálás automatikusan végbemegy.
A relációs modellben tehát nemcsak sémadefiniálással, hanem mûveletsorral is lehet egy új relációt létrehozni. Ezen relációk rendszerint nem is kapnak külön nevet, sémájuk és elôfordulásuk adatai sem tárolódnak a rendszerben. Az olyan relációk, melyek megadása nem sémájuk leírásával, hanem már létezô relációkon értelmezett mûveletsorral történik, leszármaztatott relációknak nevezik. Tulajdonképpen az ideiglenes eredményrelációk is ilyen leszármaztatott relációnak tekinthetô.
Vannak viszont olyan relációk is, melyek definíciós mûveletsorát a metaadatok között megôrizzük, de magát az elôfordulását nem tároljuk az adatbázisban. Az ilyen relációt nevezik view-nak. A view igen fontos logikai függetlenség, a különbözô adatbázisnézetek függetlenítése szempontjából. A felhasználó ugyanúgy kezelheti a view-kat is mint a bázisrelációkat, ezáltal a felhasználó elôl rejtve marad, hogy voltaképpen a view nézetken vagy a bázisrelációkon dolgozik-e, tehát felhasználó csak egyféle relációtípust lát maga elôtt.
A bázistábla, view és snapshot viszonyának szemléltetésére vegyünk egy példát. Tegyük fel, hogy egy válalt dolgozóiról kívánunk információt nyilvántartani, mely során a teljes lista mellett gyakran szükségünk lesz az 50 év feletti dolgozók listájára, valamint az éppen szabadságon lévõ dolgozók listájára.
A tervezés során egyik döntési változat az, hogy mindhárom táblát megvalósítjuk. Ennek a megoldásnak van azonban van egy lényeges hátránya. A probléma az, hogy ezen táblák adati nem függetlenek egymástól, hiszen minden 50 év feletti dolgozónak is benne kell lennie a teljes dolgozói táblában és ott egy 50 évnél nagyobb korral kell szerepelnie. Hasonlóan megadható, hogy minden szabadságon lévõ dolgozónak is szerepelnie kell a teljes táblában. A függõség azonban azt jelenti, hogy az egyik változása maga után vonja a másik tábla változását, illetve bizonyos módosítássokkor több helyen is el kell végezni a módosítást. Ha ezt nem végezzük el tökéletesen, az adatbázis ellentmondásos állapotba kerül.
A három alaptábla helyett tehát jobb megoldás, ha csak azt tároljuk alaptáblában, ami feltétlenül szükséges, amibõl a többi adat meghatározható, levezethetõ. A három listából a teljes lista szerepel ilyen bázisadatként, míg a másik kettõ származtatott adat. A származtatott adatokat tehát nem érdemes külön alaptáblába tenni. A származtatott táblák tárolására kétféle megoldás kínálkozik: a view és a snapshot.
A view esetében nem hounk létre külön táblát az adatbázisban, azaz nincs extra helyfoglalás. A view nem más mint a származtatási mûveletsor, azaz azon mûveletsor, amely megadja, hogy az alaptáblából milyen lépéseken keresztül hozható létre a kívánt lista. A view-ra történõ hivatkozáskor a rendszer lejátsza a kijelölt mûveletsort, tehát elõállítja az igényelt táblát.
A snapshot esetében viszont elõáll induláskor a lista és meg is õrzõdik az adatbázisban, mint egy csak olvasható tábla. Mivel az alaptábla idõközben megváltozhat, a snapshotban tárolt lista elavulhat, vagyis a snapshot már rég nem azt a listát tartalmazza, amit az aktuális alaptábla szerint mutatnia kellene. Ezért a snapshot-ok esetében idõnként frissítést szoktak végezni, ami azt jelenti, hogy megadott idõközönként a rendszer az aktuális aéaptábla alapján újra elvégzi a lista elõállítását és az eredménnyel helyettesíti a korábbi snapshot táblát.
Mind a view-nak, mind a snapshot-nak vannak bizonyos hátrányai. A view hátránya, hogy a hivatkozásakor kell a mûveletsort végrehajtani, így a kiadott parancs végrehajtási idejét növeli. A snapshot hátránya viszont, hogy helyet foglal és emellett a frissítések is lekötik a rendszer idejét. Így mérlegelnünk kell, hogy mely megoldást is válasszuk. A view akkor célszerû, ha viszonylag ritkán van a listára szükség és gyakran változik a lista értéke. A snapshot a gyakran igényelt, viszonylag ritkábban változó listák esetében lesz megfelelõ megoldás. A példánkban így a szabadságon lévõket inkább view-nak, az 50 év felettiek adatait pedig snapshotban tárolhatjuk.
A relációk után maga az adatbázis jelenti a kövekezô strukturális szintet. A relációs adatbázis szerkezetileg a logikailag összetartozó relációk összességét jelenti, ahol az összesség itt halmazként értelmezhetô, azaz a relációk egy halmazát tekintetjük adatbázisnak. Pontosabban fogalmazva a relációk halmaza az adatbázis szerkezetét definiálják.
A relációs adatbázisséma a relációs sémák egy halmazát jelenti. Az adatbázis séma egy elôfordulása pedig a relációsémák elôfordulásainak egy halmaza lesz. Az adatbázisséma megadása a nevével és a szerkezetével történik. Mivel a relációs modellben nem kell az adatbázis sémahoz fixen rögzíteni az oda tartozó relációk körét, az adatbázis séma tetszôleges bármikor módosítható, ezért egy új adatbázis séma létrehozásakor elegendô csak a séma azonosító nevét megadni. Tehát egy üres sémát hozunk létre, mely a késôbbiekben bármikor dinamikusan változtatható. Ez úgy történik, hogy elôbb kijelöljük az adatbázissémát, majd az ezt követô reláció séma létrehozások és törlések mind erre az adatbázissémára fognak vonatkozni.
Amint látható, a relációs adatmodell szerkezeti elemeibôl hiányoztak a kapcsolatok leírására, tárolására vonatkozó elemek. Nincs olyan kapcsolat rögzítô modellszerkezet, mint a set vagy a PCR volt az elôzôekben ismertetett adatbázismodellekben. A relációs modellben a kapcsolatok nem szerkezeteken keresztül valósul meg, hanem adatokon keresztül, pontosabban adatértékeken keresztül. Ez azt jelenti, hogy ha valamely két egyedtípus között kapcsolat áll fenn, akkor a megfelelô rekord-elôfordulásokban is léteznie kell olyan mezôknek, melyekben tárolt értékek utalnak a kapcsolatra. Így például, ha egy autó és egy ember közötti kapcsolatot, pl. a tulajdonosi kapcsolatot szeretném tárolni, akkor vagy az autó rekordba teszünk be egy tulajdonos mezôt, melynek értéke a tulajdonost azonosítja.

A példában az autók és az emberek közötti tulajdonosi kapcsolatot mezõk értékegyezõsége alapján tartjuk nyilván. Az autok táblában szerpel egy tulaj mezõ, amely a tulajdonos ember azonosító kódját tartalmazza. Az emberek táblában az isz mezõ egy kulcsmezõ szerepet tölt be, azaz minden sorban más és más az isz mezõ értéke. Az ember egyed kijelölésére így ezen mezõ használható, ezért az autók tábla tulaj mezõje is a megfelelõ ember, vagyis a tulajdonos ember isz tulajdonságának értékét tartalmazza. Mivel két azonos isz nem fordulhat elõ az emberek táblában, így a tulaj mezõben megadott hivatkozás egyértelmû. A példában az r1 autó Gáborhoz, az r4 autó Ilonához, az r2 autó Lászlóhoz, az r8 autó Gáborhoz, az r6 autó Péterhez és az r5 autó Tiborhoz tartozik.
Általánosságban a kapcsolat jellegétôl függ, hogy melyik rekordba tesszük be a kapcsolat leírására szolgáló mezôket. Mivel itt nincs rögzített kapcsolatszerkezet, az adatok értékei hordozzák a kapcsolatot, ez egy sokkal nagyobb rugalmasságot jelent, hiszen elvileg bármely két mezôt kapcsolatba hozhatunk egymással. Itt is vannak azonban bizonyos korlátok melyek elsôsorban abból erednek, hogy egy mezôben csak egy elemi érték tárolható. Emiatt egy rekord kapcsoltait is csak szûkebben értelmezhetjük, s ha például a kapcsolat az adatok egyezôségén alapszik, ami a leggyakoribb eset, akkor egy rekord csak egy másikkal tud kapcsolatban állni, ami már jelzi, hogy lesznek bizonyos nehézségeink az M:N jellegû kapcsolatok ábrázolásánál.
A relációs mdoellben az említett struktúrális elemeken kívül más építõ elem nem definiált. Összefoglalva a struktúrális rész leírását, megállapítható, hogy az adatbázis relációk összessége, ahol egy reláció azonos felépítésû rekordok halmazát jelenti. Az adatbázis szerkezetének megadásakor az adatbazásiba tartozó relációk azonosító nevét és szerkezetüket kell felsorolni. Egy reláció szerkezetét a hozzá tartozó mezõk nevének és tipusainak (domain) a felsorolásával lehet megadni. A relációs modellben nem létezik külön kapcsolatleíró struktúra elem, mivel a rekordok közötti kapcsolatok a mezõk értékein keresztül valósíthatók meg.
Relációs adatmodell integritási komponense
A relációs modellhez kapcsolódik néhány olyan alapfogalom is, amely nem közvetlenül az adatszerkezethez kapcsolódik, hanem az adatbázis integritásához. Az integritásôrzés fontosságát, egyenrangúságát mutatja, hogy Codd is külön önálló fejezetben tárgyalta az integritásôrzés problémáját.
Az integritási szabályok célja az adatbázis elõfordulások lehetséges, megengedett körének behatárolása. Az integritási szabályok tehát az adatbázisban lévõ adatelõfordulásokra adnak megszorításokat. Az integritási szabályokat csoportosíthatjuk aszerint, hogy milyen szinten fogalmazzák meg a megkötéseket. A relációs adatmodellben az alábbi három szintet szokás megkülönböztetni:
- domain szint
- rekord szint
- reláció szint
- adatbázis szint
A domain szinten egy mezõre vonatkozó értékelõfordulások körét lehet megadni. A megkötést egy logikai kifejezéssel lehet megadni, amely minden lehetséges domain értékre egy igaz vagy hamis értéket ad vissza. Az adatbázisba csak olyan mezõértékek tárolhatók le, melyekre a kijelölt feltétel igaz értéket ad vissza. Az a megkötés például, hogy a rendszám elsõ három karaktere nem lehet szám, domain szintû integritási feltételt jelent, hiszen az ellenõrzés csak egyetlen egy domain érint, egy önálló mezõ ellenõrzési feltételt szab ki.
A rekordszint esetén egy teljes rekord elfogadhatóságát döntjük el. Az ellenõrzési feltételben a relációsémában szereplõ mezõk szerepelhetnek. Az integritási feltétel célja az egy rekordon belül egymáshoz kapcsolódó mezõk értékeinek vizsgálata. Példaként vehetünk egy olyan megkötést egy minta autókereskedõ nyilvántartási rendszerbõl, mely szerint a katalizátoros autóknál az A vagy B adókulcs alkalmazható. E feltétel ellenõrzéséhez elegendõ egyetlen egy rekordelõfordulást önmagában vizsgálni.
A relációszíntû ellenõrzéshez a teljes relációt, azaz több rekordelõfordulást is át kell vizsgálni. Az a megkötés például, hogy a mezõûben ugyanaz az érték nem fordulhat elõ többször a relációban, csak úgy ellenõrizhetõ, ha ismerjük a relációban tárolt összes mezõértéket. Így e egyediséget elõíró feltételt relációszintû integritási feltételnek tekintjük. A relációszintû ellenõrzési feltétel megfogalmazódhat egy aggregációs értékre vonatkozó megkötésben, például, amikor elõírjuk, hogy az autók átlagéletkora nem lehet 12-nél több.
Az adatbáziszintû megkötések esetében a feltétel több relációban szétszórtan elhelyezkedõ mezõkre vonatkozik. Ekkor az ellenõrzéshez több reláció adatait is át kell olvasni. Erre példa az a megkötés, amikor elõírjuk, hogy az autó tipuskódjának szerepelnie kell a tipusok reláció valamely rekordjának kód mezõjében.
Az integritási feltételek egy másik szempont szerinti csoportosításában az osztályozás az alapján történik, hogy a feltétel az adatbázis egy konkrét állapotára vagy egy állapot átmenetére vonatkozik. Az állapotra vonatkozó feltételeknél egy konkrét adatbázis elõfordulást vizsgálunk, függetlenül a korábbi vagy késõbbi adatbázis állapotoktól. Az a feltétel például, hogy egy mezõ értéke nem lehet üres, kitöltetlen, állapot integritási feltételnek tekintendõ. Ha a feltétel azonban az állapotok megváltozását érinti, akkor egy állapotátmenet integritási feltételt kapunk. Erre példa lehet az a megkötés, mely szerint a fizetés értéke nem nõhet 25 százaléknál jobban. Ezt a feltételt úgy lehet ellenõrizni, hogy a az adatbázis módosítás elõtti és módosítás utáni állapotából a két fizetésértéket összehasonlítjuk, és megállapítjuk a változás mértékét.
Az egyes integritási feltételeknél az elõzõek mellett még abban is különbsééget szokták tenni, hogy mikor kerül sor az integritási feltétel ellenõrzésére. Vannak ugyanis olyan ellenõrzési feltételek, mint például a domain szintû mûveletek, melyekben az ellenõrzés rögtön, az adatelem módosulásakor bekövetkezik. Ez a végrehajtási mód jellemzõ a legtöbb integritási feltételre. Vannak emellett azonban olyan több elemet érintõ, összetettebb integritási feltételek, melyek nem feltétlenül teljesülnek a végrehajtás minden pillanatában. Vagyis az adatbázis nincs minden idõpontban konzisztens állapotban. Az adatbáziskezelésben ezért a tevékenységeket nagyobb csoportokba szokták bontani, mely egységek ehgyfajta konzisztenica egységet is jelentenek. Eszerint az adatbázisnak nemsz ükséges minden idõpontban konzisztensnek lennie, elegendõ e tevékenységek egységek végén biztosítani a megkívánt állapotot. Az ilyen integritási feltételek esetén az ellenõrzést csak késõbb idõpontban vizsgálják, ezért ezeket késleltetett ellenõrzésû integritási feltételeknek nevezik.
A következõkben a relációs modellben megfogalmazott alapvetõ integritási feltételeket foglaljuk össze.
Mint már ismert, az egyedek megkülönböztetése tulajdoságértékeik alapján történik, s a helyesen megtervezett adatmodellben minden egyedtípushoz kell léteznie olyan tulajdonságcsoportnak, mely egyértelmûen meghatározza az egyed elôfordulásait. Az ilyen mezôcsoportot nevezik kulcsnak. A kulcs lehet egyszerû, ha egyetlen mezôbôl áll, pl. az autó esetén a rendszám egy egyszerû kulcsnak tekinthetô, vagy lehet összetett, amikor a kulcs több mezôbôl épül fel. Egy tanfolyamot egyértelmû azonosításához például a címe mellett szükség van a rendezô intézet és az idôpont megadására is. Ebben az esetben e három mezô együttese alkotja a kulcsot. A kulcsok kiemelésére a relációk táblázatos megadásánál a kulcsmezõket aláhúzással jelölik meg. Az alábbi ábrán egy egyszerû és egy összetett kúlcsú relációt láthatunk.

A kulcs azonban megfogalmazható más megközelítésbôl is, úgy mint egy integritási feltétel. Ugyanis egy mezôcsoportot akkor tekintünk kulcsnak, ha minden rekord elôfordulásnál különbözô értékeket vesz fel, azaz nem fordul elô egy érték soha sem többször a relációban. Ez formálisan azt is jelenti, hogy minden elemére a relációnak:
ha t1 nem egyenlô t2, akkor t1[kulcs] nem egyenlo t2[kulcs]
teljesül. Adott egyedtípus esetén elôfordulhat, hogy több mezôt is kiválaszthatnánk kulcsként, mint pl. az autók esetén a rendszám mellett az alvázszám is egyértelmûen azonosít egy autót. Hogy egy mezôcsoport kulcsként szerepelhessen természetesen teljesítenie kell a fenti megkötést, és ebben az esetben jelölt (candidate) kulcsnak is nevezik. A gyakorlatban ekkor természetesen választanunk kell, hogy melyik jelölt legyen a tényleges kulcs, hiszen ettôl függôen kell az adatmodell többi elemét is megválasztani.
A kulcs több, más vonatkozásban is szerepet játszik, pl. az adatelérést gyorsító indexek létrehozásában. A hatékonysági megfontolásokat követve rendszerint a legrövidebb jelölt kulcsot választják valódi kulcsnak, ugyanis ekkor lesz más relációk mérete is a legrövidebb, illetve az indexszerkezet is kevesebb helyet foglal el, és ezáltal gyorsabb is lesz az elérés. Ezért a kulcsra vonatkozólag a következô megkötéseket szokták tenni:
- egyediség, azaz nem ismétlôdik az értéke a táblában
- minimális, vagyis nincs olyan valódi részhalmaza, mely kielégítené az elôzô két feltételt
A kulcs mezõhöz kapcsolódóan egy fontos integritási szabály foglamazható meg a relációs modellben. Ezt a szabály egyed-integritási (entity-integrity), szabálynak nevezik. E szab'ly azt mondja ki, hogy bármely relációnál legyen kulcsmezõcsoport és a kulcsmezõcsoport nem lehet, még részlegesen sem üres, azaz NULL érték. A részlegesen üres kulcs akkor lehetséges, ha a kulcs nem elemi, hanem több mezõ együttesébõl áll.
E szabály lényege tehát hogy minden alaptáblában tárolt egyednek legyen egyedi azonosító kulcsa, mely egyetlen egy esetben sem lehet üres. Másképp megfogalmazva, azt is mondhatrjuk, hogy a relációs modellben csak olyan rekordokat tárolhatunk, melyeknek van egyedi azonosító, kulcsmezõje, tehát minden rekordja, sora egyértelmûen megkülönböztethetõ egymástól.
Az integirtási feltételnek elget tévõ kulcsmezõcsoportot, azaz a kiválasztott, fenti feltételeknek megfelelô kulcsot szokás elsôdleges kulcsnak is nevezni. A többi tábla mérete azért is csökkenthetô az elsõdleges kulcs rövidítésével, mert az egyedek közötti kapcsolatok mint már mondtuk, az adatértékeken keresztül valósulnak meg. Tehát létezik a kapcsolódó relációban egy olyan mezô, mely a hozzá tartozó másik típusú egyedet jelöli ki, s az egyértelmû azonosításhoz a kulcs használható fel. Így a kapcsolódó reláció tartalmazni fog egy olyan mezôt, mely a kapcsolat jelzésére szolgál, s ugyanaz a domain tartozik hozzá, mint az alapreláció kulcsához. A kapcsolódó táblában ez a mezô, vagy mezôcsoport természetesen már nem lesz kulcs, de mivel jelentése, szerepe különbözik a többi normál tulajdonságot ôrzô mezôktôl, ezért ezt a mezôt kapcsoló kulcsnak (foreign key) nevezik.
A kapcsolatok tárolásához tehát a kulcsot más relációkban is megismétlik, ezért úgymond többszörösen is kifejti a hatását a kulcs hosszának növelése. Mindezek már sejtetik a relációs modell azon tulajdonságát, hogy a kapcsolatok tárolására mesterséges mezôket kell befûzni a relációsémába, amelyek nem az egyed természetes jellemzôit hordozzák, hanem kapcsolatának jellemzôit. Tehát a kapcsolatokat nem a rekordokon kívül írjuk le, mint ahogy a hálós és hierarchikus modelleknél tettük, hanem a rekordon belül, a mezôk kibôvítésével jelöljük a kapcsolat létezését.
A kapcsoló kulcs egy hivatkozást jelképez, amikor is az egyik relációból hivatkozunk egy másik reláció valamely rekordelôfordulására. A kapcsoló kulcsokkal megvalósított hivatkozások szemléltetésére szokás használni a hivatkozási diagramot, mely a relációkat, és a közöttük fenálló hivatkozásokat mutatja. Mivel egy relációra lehet hivatkozni és egyidejûleg a reláció is hivatkozhat más relációkra, ezért a diagrammon hivatkozási láncokat láthatunk, melyek speciális esetben kört is alkothatnak. A hivatkozások egyik speciális fajtája az önhivatkozás, amikor egy reláció elôfordulásai ugyanazon reláció egy másik elôfordulására hivatkoznak. Ilyen eset léphet fel, ha pl. a dolgozók táblában nyilvántartjuk, hogy kinek ki a közvetlen fônöke, hiszen azok is dolgozók lesznek így a beosztott és a fônök is ugyanabban a relációban foglalnak helyet.
A kulcshoz hasonolóan a kapcsoló kulcshoz is kapcsolható egy integritási feltétel is, mely szerint a kapcsoló kulcsnak létezõ egyedre kell mutatnia. Tehát amíg kulcs esetén teljesülnie kellett a reláción belüli egyediségnek, addig a kapcsoló kulcs esetén léteznie kell olyan rekordnak a másik relációban, melynek kulcsértéke megegyezik a kapcsoló kulcs értékével. A kapcsoló kulcsnak tehát a következõ feltételeket kell teljesítenie:
- értéke vagy üres
- vagy pedig a hivatkozott tábla kulcsmezõi között szerepel
Ezt a szabálya a referential integrity, azaz hivatkozási integritásai szabálynak nevezi az irdalom.
Az ábrában két elsõdleges kulcsot és egy kapcsoló (idegen) kulcsot láthatunk. Az EMBEREK tábla elsõdleges kulcsa az isz mezõ, míg az AUTÓK tábláé az rsz mezõ. Az AUTOK tábla taratlmaz egy kapcsoló kulcsot, s ez a tulaj mezõ. E mezõ az EMBEREK táblához kapcsolja az AUTÓK táblát, s minden nem üres értéke valamely isz mezõ értékével egyezik meg.
A két integritási feltételt összehasonlítva látható, hogy az egyikben, mégozzá a kulcs mezõ feltételnél, csak egy tábla adatait kell átolvasni a feltétel ellenõrzéséhez, addig a másik,kapcsoló kulcs esetén másik tábla adatait kell is át kell nézni. E különbségen alapul véve, az integritási feltételeket felbontják lokális és globális feltételekre.
A lokális integritási feltételek köre azon feltételeket foglalja magába, melyek egyetlen egy tábla adataira vonatkoznak. A kulcs integritási feltétel egy ilyen lokális feltételt jelent.
A globális integritási feltétel esetén a feltétel több táblából származó adatokat is érint. A kapcsoló kulcs feltétel ebbe a csoportba esik.
Az integritási feltételekben megadott követelményeknek a modell érvényességi élettartama alatt fenn kell állnia, tehát egy integritási feltételként mindig teljesülnie kell. Így ha kijelölöm a rendszámot az autó reláció kulcsának, akkor nem fordulhat elô, hogy két rekord is ugyanazon kulcsértékkel szerepel a relációban. Erre ügyelnie kell a rendszernek az új rekordok beszúrásakor, illetve a rekordok módosításakor. Természtesen a tervezõ a valós világ változásait követve módosíthatja az adatbázisban letárolt integritási feltételeket is. Az adatbázisban tehát nemcsak a struktúrák, a bennük tárolt adatok, hanem az adatokra vonatkozó integritási szabályok is változhatnak.
A kulcs esetén az egyik megszokott integritási feltételelem volt, hogy a mezônek mindig hordoznia kell egy valós értéket. Ezt úgy is mondhatjuk, hogy a mezô nem lehet üres, azaz kitöltetlen. Az üres, kitöltetlen érték, amit az adatbáziskezeláésben a NULL szimbólummal jelölünk, egy önálló érték a relációs modellben, mégpedig egy fontos szerepet játszó érték. A NULL érték nem azonos az 0 értékkel, mert az egy értékes, valós adat lehet. Az RDBMS-ek rendszerint külön jelzôvel jelölik, ha egy mezô még nem kapott értéket, tehát ha nincs benne letárolt adat. Ekkor mondjuk, hogy a mezô a NULL értéket tartalmazza.
A hagyományos programozási nyelvek változói rendszerint nem tudják megkülönböztetni az értékes, felvitt adatértékeket, a szemét, a véletlenül, az allokáláskor ott maradt értékektôl megkülönböztetni. A relációs modellben viszont lehetôség van NULL értékek megkülönböztetésére, ellenôrzésére.
A hivatkozási integritási szabály szoros kapcsolatban áll a NULL értékkel hiszen, mint láttuk e feltétel megengedi, hogy a kapcsoló mezõ üres, azaz NULL értékû legyen. Ez azt jelenti, hogy az egyed nem kapcsolódik másik egyedhez. Ezzel kapcsolatban egy érdekes probléma, hogy több mezõbõl álló kapcsoló kulcs esetén miként értelmezzük a NULL értéket. Mivel az elsõdleges kulcs esetén az összetett kulcsnál egyetlen egy tagmezõ sem lehet üres, azaz a NULL érték sehol sem fordulhat elõ az elsõdleges kulcson belül, ezért egy olyan kapcsoló kulcs, amely bizonyos mezõiben nem õres, másokban meg üres, nem mutathat egyetlen egy létezõ elsõdleges kulcsra sem. Így ez a kapcsoló kulcs érvénytelen, értelmetlen hivatkozás. Emiatt a relációs modellben nem engedünk meg olyan kapcsoló kulcsokat, melyek bármely tagmezõje üres lenne. Az integritási feltételben a megengedett NULL érték tehát azt jelenti, hogy a kapcsoló kulcs minden mezõje NULL értékû. Tehát vagy minden tagmezõ üres vagy egyik sem üres.
A hivatkozási integritási feltétel a NULL értékek kezelése mellett az adatok módosításánál is nagyobb körültekintést igényel. Az elviekben megengedettnek vált módosítások során is elõfordulhatnak ugyanis olyan állapotok, amikor a feltétel nem teljesül. Ha ugyanis egy hivatkozott elsõdleges kulcsérték megváltozik, akkor a korábbi kapcsoló kulcsok nem létezõ értékekre fognak mutatni, ami nem megengedett állapot. Ezért ebben az esetben a leggyakoribb kerülõút az, amikor a kapcsoló kulcsok értékét elõbb NULL értékre állítjuk, majd elvégezzük az elsõdleges kulcs módosítását, s legvégül beállítjuk a kapcsolókulcs új értékét.
A relációs modellben megvalósításra kerültek a fenti integritási feltételek mellett még két, a mezôk értékére vonatkozó feltétel is. Az értékellenôrzési feltétellel megadhatunk egy logikai kifejezést, mely minden alkalommal, amikor a mezôbe új értéket viszünk be, kiértékelésre kerül, s ha a kifejezés igaz értéket vesz fel, akkor letárolásra kerül az érték, ha pedig hamis lett a kiértékelés eredménye, akkor nem engedi a rendszer letárolni az új értéket.

A példában a B mezôbe csak 23-nál nagyobb értékeket lehet letárolni.
Míg az elôzô feltétel egy új elem az ER modellben megismert elemekhez képest, addig a másik, eddig még nem említett feltétel már az ER modellben is megtalálható volt. Szerepel az ER elemek között ugyanis a leszármaztatott tulajdonság fogalma is, s elterjedtsége miatt a relációs modellbe is átkerült a fogalma, s a legtöbb rendszer támogatja is hogy egy mezôbe más mezôkben tárolt értékek alapján kiszámított értéket tároljunk, úgymond egy virtuális mezôt létrehozva, hiszen adatai nem kerülnek letárolásra az adatbázisban, csak a kiszámítási képlete. Bizonyos rendszerekben a leszármaztatott mezôket nem lehet közvetlenül a bázisrelációkba elhelyezni, csak a leszármaztatott relációkban szerepelhetnek.
Összefoglalóan tehát a következô adatintegritási elemek állnak a rendelkezésünkre a relációs modellben:
- elsôdleges kulcs
- kapcsoló kulcs
- egy mezôérték nem ismétlôdhet
- nem maradhat a mezô üres
- mezô értékellenôrzése
- mezô kiszámított értéket tárol
Relációs stuktúra és integritási feltételek formális megadása
Az eddigiekben a relációs adatmodellt szövegesen, informálisan írtuk le. Ez a leírási mód igen könnyen érthetõ, könnyen megjegyezhetõ, azonban van egy hátránya, hogy a hétköznapi szavaink sok esetben többértelmûek, s másrészrõl a szöüveges leírások viszonylag nagy terjedelmûek. Amint láthatjuk, itt is több oldalt szenteltünk a struktúrális és integritási rész ismertetésére. Tömörség és egyértelmûség tekintetében a formális leírások elõnyösebbek az informális leírásoknál.
A relációs modell e tekintetben sem vall szégyent. Ez a modell volt tulajdonképpen az elsõ olyan adatbázismodell, amely formális, matematikai alapokon nyugszik. A formális alapok lehetõvé tették a modell egzakt elemzését, a modell késõbbi továbbfejlesztését. A következõkben röviden összefoglaljuk a relációs modell struktúrális és integritási részének formális leírását.
Attributum és domain értelemzése:
Legyen adott egy U nemüres, véges halmaz, amit univerzumnak nevezünk. E halmaz foglalja magába a vizsgált problématerület azon fogalmait, melyek értékeit egy skalár értékkel meg lehet adni. Egy videokölcsönzõ esetén az U halmaz olyan fogalmakat foglal magába, mint pl. a klubbtag neve, kazetta címe, kölcsönzés ideje, stb. E fogalmak nagyságát mind egy-egy skalár értékkel, egy számmal vagy egy sztringgel lehet leírni.
Az U halmaz elemeit attributumoknak nevezzük: A Î U. Az attributum tehát a tulajdonság fogalomhoz áll közel, példánkban, mind a a klubbtag neve, kazetta címe, kölcsönzés ideje egy-egy attributum lesz.
Legyen D = { D1, ..., Dm} nemüres halmazok véges halmaza, azaz minden Di egy ujabb halmaz. Egy Di halmazt domain-nek, vagy értéktartománynak nevezünk, elemei tetszõleges skalár értékek.
Feltesszük, hogy létezik egy dom : U ® D leképzés, melyben minden elem képé válik, azaz minden A Î U-hoz hozzárendelhetõ egy Di Î D. Az A-hoz hozzárendelt Di-t dom(A) szimbólummal jelöljük és az A attributum domain halmazának nevezzük. A w Î dom(A) egy, az attributum által felvehetõ értéket jelöl. Példánkban 90 Î dom(film hossza) teljesül, hiszen a film hosszát egész számokkal, percben mérve adjuk meg, s ez az érték lehet 90 perc. Ezzel szemben 'Jani' Ï dom(film hossza), hiszen a megadott attributum értéke csak egész szám lehet.
Relációséma és reláció értelmezése:
Az R Í U halmazt relációsémának nevezik. Az R tehát nem más mint attributumok egy véges halmaza. A relációséma reláció szerkezetét írja le megadva a relációhoz tartozó attributumokat. A példánkban az {klubbtag neve, életkor, lakcím, azonosító szám} halmaz egy reláció szerkezetét adja meg. A definícióból léátható, hogy nem kötöttük ki a nemüres jelleget, illetve egy attributum több különbözõ relációsémában is szerepelhet.
Egy R felett értelmezett r relációnak, amit az r(R) szimbólummal jelölünk, az R felett értelmezett t leképzések egy véges halmazát értjük. Pontosabban megfogalmazva, ha R = {A1, ..., Am}, akkor
r(R) = { t : R ® È m Di | " i: t(Ai) Î dom(Ai) }
A t szimbólum, melyet angolul tuple-nek neveznek. s amit mi rekordnak, sornak fordítottunk, egy leképzés, amely a relációséma minden attributumához hozzárendel egy elemet az attributum értékkészletébõl.
A reláció, melyet mi egy táblázattal reprezentáltunk e értelmezésben leképzések halmaza. A táblázat minden sora egy önálló léképzés. E felírási mód magában foglalja a rellációk azon tulajdonságát, hogy két azonos felépítésû sor (illetve leépézés) nem szerepelhet. A halmazban ugyanis minden elem csak egyszer fordulhat elõ.
Egy R sémához több különbözõ r(R) reláció is tartozhat, hiszen több különbözõ halmaz is képezhetõ a lehetséges leképzésekbõl. Az R séma felett értelmezhetõ r(R) relációk halmazát REL(R) szimbólummal jelöljük, melynek pontos jelentése tehát: REL(R) = { r | r(R)}.
Lokális integritási feltételek értelmezése:
Egy b : REL(R) ® {igaz, hamis} leképzést az R séma feletti lokális integritási feltételnek nezünk. A b leképzés minden lehetséges R feletti relációhoz hozzárendeli vagy az igaz vagy a hamis logikai értéket. A b tehát minden r(R)-rõl eldönti, hogy elfogadható-e, azaz megfelel-e a kritériumoknak vagy sem. A b így megszûri a lehetséges relációkat, megkülönböztetve a feltételeknek elget tévõ illetve a feltételeket nem teljesítõ relációkat.
Az R felett értelmezett b integritási feltételek halmazát B -vel jelöljük. A B tehát magába foglalja az összes megalkotott integritási feltételt, amely az R relációsémára vonatkozik.
Egy adott R relációsémát a hozzá tartozó integritási feltételek B halmazával együtt kibõvített relációsémának nevezünk. A kibõvített relációséma jele R. Ekkor R = (R, B) teljesül. Egy R feletti relációnak, melynek jele r(R), olyan relációt nevezünk, amley egyrész reláció R felett másrészt teljesít minden B-beli integritási feltételt:
r(R) = { r | r(R) és " b Î B : b(r) = igaz }
Tehát r(R) egy megengedhetõ relációt reprezentál.
Adatbázisséma és adatbázis értelmezése:
A relációs sémák egy halmazát nevezzük adatbázissémának, melynek jele S. Az S = {R1, ... , Rn} séma az adatbázis szerkezetét aja meg. Az adatbázis szerkezete tehát a benne tárolt relációk szerkezeteinek összességével egyenlõ. Ez is mutatja, hogy a relációs modellben nincsennek különállóó kapcsolatleíró elemek.
Az adatbázis egy adatbázis sémára idomuló adatrendszer, jele d. Az adatbázis formális megadása a következõ:
d(S) = {r1(R1),...,rn(Rn)} ahol S = {R1, ... , Rn}
Az r Î d relációkat a d adatbázis alap- vagy bázisrelációinak nevezzük.
Ha az S sémát nem az egyszerû relációsémákkal állítjuk fel, hanem a kiterjesztett sémákkal, akkor az elõálló adatbázist lokáli integritási feltételekkel kiterjesztett adatbázisnak nevezzük:
d(S) = {r1(R1),...,rn(Rn)} ahol S = {R1, ... , Rn}
Globális integritási feltételek értelmezése:
A több relációra kiterjedõ feltételekre, mint az adatbázison értelmezett függvényekre tekinthetünk. Egy g : d(S) ® {igaz, hamis} függvényt nevezünk globális integritási feltételnek. A g leképzés minden lehetséges S feletti adatbázishoz, reláció halmazhoz hozzárendeli vagy az igaz vagy a hamis logikai értéket. A g tehát minden d(S)-rõl eldönti, hogy elfogadható-e, azaz megfelel-e a kritériumoknak vagy sem, így a g megszûri a lehetséges adatbázisokat, megkülönböztetve a feltételeknek elget tévõ illetve a feltételeket nem teljesítõ adatbázisokat.
Az S felett értelmezett g integritási feltételek halmazát G -vel jelöljük. A G tehát magába foglalja az összes megalkotott integritási feltételt, amely az S adatbázissémára vonatkozik.
Adott S adatbázisséma és G globális integritási feltételhalmaz esetén a feltételnek megfelelõ, S séma feletti adatbázisok halmazát a DAT(S) szimbólummal jelöljük.
Kulcs integritási feltétel jelentése:
A kulcs attributumok felfoghatók egyfajta lokális integritási feltételként, amely akkor ad vissza igaz értéket, ha a megadott attributumcsoport teljesíti a kulcs feltétel elõírt követelményeit. A kulcsfeltétel a következõ integritási függvény formátumban adható meg:
bK(r(R)) = igaz, ha K Í R és " t1,t2 Î r(R) : t1 ¹ t2 Þ t1(K) ¹ t2(K)
különben hamis
E kifejezés azt mondja ki, hogy a kulcsnak a relációsséma részének kell lennie és két különbözõ rekord, tuple esetén a kulcsban különbözni kell egymástól a rekordoknak.
Idegen kulcs integritási feltétel értelmezése:
Az idegen, kapcsoló kulcs is értelmezhetõ integritási feltételként, mégpedig egy globális integritási feltételként. A kapcsoló kulcs szerkezet kijelöléséhez két reláció egy-egy mezõcsoportját kell kijelölni, így ezeket, mint paramétereket meg kell adni az integritási függvénynél:
g X,Y(r1(R1),r2(R2)) = igaz, ha YÍ R2, X Í R1 és bY(r2) = igaz és
{t(X)|tÎ r1} Í {t(Y)|tÎ r2}
különben hamis
A feltétel azt mondja ki, hogy az Y attributum az r2(R2) relációban kulcs legyen és emellett az X attributumokon felvett értékek legyenek benne az Y kulcs által velvett értékekben.
A most ismeretett formalizmusra támaszkodva a késõbbi fejezetek során is, a mûveleteket leíró és az adatbázis tervezésrõl szóló részekben, pontosabban megfogalmazhatók lesznek a relációs algebra további elméleti alapjai.
Az EE/R modell konvertálása relációs adatmodellre
Az adatbázis tervezése során az elemzés eredményeképpen összegyûjtött információkat szemantikai modell leírásban szokás megadni, s ez a szemantikai modell lesz az alapja a tervezésnél elôállított adatbázis modellnek. Az adatbázis tervezés egyik fontos lépése tehát a szemantikai modellnek adatbázismodellbe történô konvertálása.
Mivel elsôdleges feladatunk a relációs adatmodell elsajátítása, s a relációs modellhez legszorosabban kapcsolódó szemantikai modell az E/R modell illetve az EE/R modell, ezért a továbbiakban az EE/R és a relációs modell konverziójának kérdéseire koncentrálunk.
A konverzió során az EE/R modellelemeket relációs modellelemekkel kell megvalósítanunk. Az átalakítás nehézsége abban rejlik, hogy egyrészt bizonyos EE/R fogalmaknak nincs meg a relációs modellbeli megfelelôje, másrészt míg a EE/R modell szemantika orientált, addig a relációs modellben már más, haték onysági, integritásôrzési szempontok is érvényesülnek. Elsôként azt nézzük meg, hogy az EE/R modell egyes elemei hogyan képezhetôk le a relációs modellre, majd késôbb elemezzük a relációs modell hatékonyságát, jóságát.
A konverzió alapelve az, hogy egy reláció egy egyedtípusnak felel meg. A relációs adatmodell egy relációja tehát egy egyedtípus elôfordulásait fogja tartalmazni. A reláció neve megegyezik az egyedtípus azonosító nevével. A reláció szerkezet is a EE/R modellbôl jön. A reláció több mezôbôl épül fel, hasonlóan ahogy az egyedtípus is a tulajdonságokból áll össze.
Tehát az elsõ szabály a konverziónál az az irányelv, hogy az egyedekbõl készítsünk relációkat, s a hozzá kapcsolódó tulajdonságok legyenek a reláció attributumai, mezõi. A követklzõ ábra egy ilyen átalakítást szemléltet.

A tulajdonság - mezô megfeleltetés azonban nem alkalmazható automatikusan, hiszen a mezô a relációs modellben csak atomi értéket hordozhat, tehát nem lehet összetett adatérték. Emiatt egy EE/R összetett tulajdonság már nem valósítható meg egy relációs mezôvel. A közvetlen leírás helyett más kerülôutat kell választani. Hasonló nehézségek fognak fellépni a kapcsolatok leírásánál is. A relációs modell a kulcs és kapcsoló kulcs segítségével tárolja a kapcsolatokat. Mivel a kapcsoló kulcs csak egy értéket tárol, ezért egy rekord-elôforduláshoz csak egyetlen egy egyedelôfordulás köthetô a kapcsolódó egyedtípusból. Tehát itt az N:M kapcsolatok tárolása fog nehézséget okozni. A következôkben szisztematikusan átnézzük az egyes EE/R elemeket és konverziós lehetôségeiket.
- egyed
megfeleltethetô egy relációnak, a reláció neve megegyezik az egyedtípus azonosító nevével.
- normál egyed: mivel van kulcstulajdonsága, ezért a tulajdonságok alkothatják a reláció mezôit, s nincs szükség kiegészítô mezôkre
- gyenge egyed: mivel ezen egyedtípus tulajdonságai között nincs olyan, mely egyértelmûen azonosíthatná az elôfordulásokat, ezért a tulajdonságok önmagukban nem elegendôek a relációhoz, hiszen a relációs modellben minden relációnak léteznie kell kulcs értékének. A gyenge egyedet egy másik, normál egyedhez fûzôdô kapcsolata azonosít. Tehát úgy lehetne egy gyenge egyedhez tartozó relációban kulcsot létrehozni, hogy a mezôk közé bevisszük a meghatározó egyedelôfordulás kulcsértékét is. Ekkor már ez a mezô együtt valamely más mezôkkel együtt már használható kulcsként. A következõ ábra a dolgozókat és gyerekeiket ábrázolja. E modellben a gyerek egy gyenge egye, mivel a dolgozó azonosítja õket egyértelmûen.

A mintában a gyerek gyenge egyed azonosítására a szülõ és a saját név együttesen szükséges, így a gyerek reláció kulcsa összetett lesz. A szülõ mezõ egyben kapcsoló kulcs, amely a dolgozó relációra mutat.
- tulajdonságok
egy tulajdonság a reláció egy mezôjének feletethetô meg
- egyszerû tulajdonság: mivel az egyszerû tulajdonság egy elemi skalár értéket vesz fel, ezért megfeleltethetô egy mezônek. A mezô neve megegyezik a tulajdonság azonosító nevével.
- kulcs tulajdonság: a tulajdonság azonosító szerepét a relációs modellben az integritási feltételekkel lehet kijelölni. A relációs modellben létezik egy olyan integritási elem, mellyel kijelölhetô, hogy melyik mezôcsoportot választottuk kulcsnak. A relációs séma megadásakor eláhúzással jelöljük ki a kulcs mezõcsoportot.
- összetett tulajdonság: a relációs modell mezô szerkezete csak atomi értékeket tárolhat, amely nem bontható fel további részekre, ezért az összetett tulajdonság nem tárolható egy mezôben. Az összetett tulajdonság leképzésére a legegyszerûbb mód, ha felbontjuk az összetett tulajdonságot alkotó elemeire, a felbontást addig végezve, amíg egyszerû tulajdonságokat nem kapunk, s ezeket vesszük be a relációba mezôknek. Természetesen, az elnevezést esetleg módosítani kell, hiszen a relációban minden mezônek egyedi elnevezést kell kapnia, míg a különbözô összetett tulajdonságok esetleg tartalmazhattak azonos nevû komponenseket.
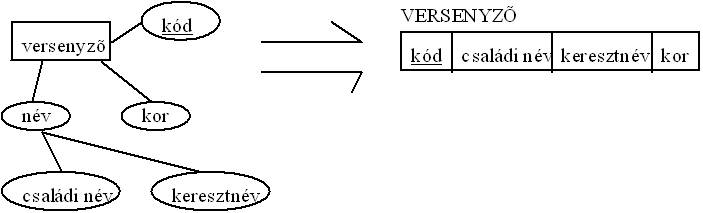
A példában a név összetettt tulajdonságot már nem szerepeltetjük a relációs sémában, mivel azt az õt alkotó tagtulajdonságokat építjük be a relációs modellbe.
- többértékû tulajdonság: Mivel a relációs modellben csak atomi értékeket tároló mezôk létezhetnek, ezért, a többértékû mezôk közvetlenül nem tárolhatók a relációban. Mivel itt egy mezôhöz egy értékhalmaz tartozna, s a halmazszerkezet a relációkhoz áll közel, ezért az összetett tulajdonságok ábrázolásának szokásos módszere, hogy létrehozunk egy újabb relációt, melybe a tulajdonságértékeket tároljuk le. Mivel így több relációba szétkerülnek az egyedtípus tulajdonságai, külön kell gondoskodnunk, hogy az összetartozó értékeket nyilvántartsuk, ezért ebbe az újonnan létrehozott relációba is bele teszik az egyedtípus kulcsmezôjét, amelynek szerepe, hogy kijelölje melyik egyed-elôforduláshoz tartoznak az egyes tulajdonságérték elôfordulások. Itt elsôként találkozhattunk a relációs modellezés egyik sajátosságával, hogy a szemantikai tartalom megôrzésére a relációkat szétdaraboljuk több relációra.

A példában a versenyszámok, mint többértékû tulajdonság szerepel. Mivel többértékû mezõt nem támogat a relációs modell, így egy különálló relációt kell létrehoznunk, melyben e tulajdonság elõfordulásai kerülnek majd letáolásra. Hogy az egyes versenyszám értékek, mely versenyzõhöz tartoznak, egy kapcsoló kulcsot is szerepeltetni kell az újonnan létrehozott relációban. E kapcsolókulcs a versenyzõ elnevezést lapta meg.
- leszármaztatott tulajdonság: A tulajdonságot normál mezôként be kell hozni a relációba, majd az integritási feltételekkel lehet kijelölni, hogy ez a mezô nem közvetlen értékeket tartalmaz, hanem más mezôkbôl származtatott értékeket. A relációs modellben létezik tehát egy olyan integritási elem, mellyel kijelölhetô, hogy melyik mezô lesz leszármaztatott. A séma grafikus mejelenítésénél normál mezõként ábrázoljuk a származtatott mezõt is.
- Kapcsolatok
a kapcsolatok jelzése a kulcs-kapcsolókulcs párosban tárolt értékek alapján történik
- 1:1 kapcsolat: mivel ennél a kapcsolattípusnál egy egyed-elôfordulás, azaz egy rekordelôfordulás, mely a másik egyedtípus egyetlen egy elôfordulásához kapcsolódhat, ezért rekord-elôfordulásonként elegendô egyetlen egy kapcsolóértéket tárolni. Tehát az 1:1 kapcsolat leképzése úgy történik, hogy az egyik rekordot kibôvítjük egy új mezôvel, mely a kapcsolókulcs szerepét fogja játszani. A mezô domain-je megegyezik a másik rekordtípus kulcsának domain-jével, s értéke azon elôfordulás kulcsértékét fogja tartalmazni, mellyel a kapcsolat fennáll. Az így megvalósított kapcsolatnak azonban még van egy szépséghibája, ugyanis a fenti szerkezetben semmi sem akadályozza meg, hogy a kapcsoló kulcsot tartalmazó relációban több rekordelôfordulás is ugyanazt az értéket tartalmazza. Ennek megvalósulása egy 1:N kapcsolatot eredményezne, ami ellentmond szemantikai modellben felállított szerkezetnek. Az ellentmondást úgy lehetne megelôzni, hogy nem engedjük meg, hogy egy kapcsolókulcs érték többször is elôforduljon. Szerencsére a relációs modell adatintegritási komponense rendelkezik ilyen eszközzel, ugyanis a mezôkhöz rendelhetô egy értékegyediséget megszabó feltétel is, így ennek megadása után már nem fordulhat elô ugyanaz a kapcsoló kulcs érték kétszer.

Az ábrán a nevezés relációhoz kapcsoltuk a bevezetett kapcsoló kulcsot, amely a versenyzõ elnevezést kapta. E mezõ tartalmazza a nevezéshez kapcsolódó versenyzõ kód tulajdonságnak értékét.
- 1:N kapcsolat: mivel ennél a kapcsolattípusnál van egy olyan egyedelôfordulás, mely a másik egyedtípus egyetlen egy elôfordulásához kapcsolódhat, ezért rekord-elôfordulásonként elegendô egyetlen egy kapcsolóértéket tárolni. Tehát az 1:N kapcsolat leképzése is úgy történik, hogy az egyik rekordot kibôvítjük egy új mezôvel, mely a kapcsolókulcs szerepét fogja játszani. A mezô domain-je megegyezik a másik rekordtípus kulcsának domain-jével, s értéke azon elôfordulás kulcsértékét fogja tartalmazni, mellyel a kapcsolat fennáll. A két egyed közül abba kerül beépítésre a kapcsolókulcs, amelyik a másik egyednek maximum egy elõfordulásával kapcsolódik. Ez a megkötés azért szükséges, mert a kapcsolókulcs mezõ, mint minden más mezõ, csak egyetlen egy értéket tárolhat. Mivel itt egy kapcsolókulcs érték több rekord-elôfordulásban is szerepelhet egy reláción belül, ezért itt nincs szükség külön integritási feltétel definiálására.

A példában a versenyzõ egyedhez kellett beépíteni a kapcsolókulcsot, hiszen egy versenyzõhöz csak egyetlen egy csapat kapcsolódik. Azért nem lehet a cspathoz tenni a kpcsoló kulcsot, mert akkor a kapcoló mezõnek több értéket is tárolnia kellene, hiszen egy csapathoz több versenyzõ is tartozhat. A relációs modellben azonban egy mezõ csak egy elemei értéket tárolhat.
- N:M kapcsolat: mivel itt mindkét, a kapcsolatban elôforduló egyedtípus elôfordulásai több másik egyedtípusbeli elôforduláshoz is kapcsolódhatnak, ezért minkét kapcsolókulcsnak több értéket kellene felvennie, ami nem megengdett. Így egyik sem tárolható a relációban mezôként. A probléma megoldása hasonlít a korábbi modellekben alkalmazott eljárásra, vagyis itt is létrehozunk egy új relációt, egy kapcsoló relációt, melynek minden rekordelôfordulása egy konkrét kapcsolatot reprezentál. Ezen új reláció kulcsának a kapcsolatot kell azonosítania, s erre a két kapcsolódó egyedelôfordulás kulcsainak együttesét szokták használni. A kapcsoló reláció kulcsa tehát magában foglalja a két kapcsolókulcsot is. Ez a megoldás lehetôvé teszi, hogy a kapcsoló relációba mezôként bevegyük azokat a tulajdonságokat is, melyek magát a kapcsolatot jellemzik, s nem csak a kapcsolódó egyedeket.

A példában a kapcsolatot egy kapcsoló reláció létrehozásával lehetett realizálni a relációs modellen belül. A kapcsoló reláció, azaz a résztvesz reláció, kapcsoló kulcsként tartalmaz hivatkozást mindkét kapcsolódó relációra. A kapcsoló reláció minden rekordja egy konkrét versenyzõ és verseny kapcsolatot tárol.
A tulajdonsággal ellátott kapcsolat bemuatására bõvítsük az elõzõ ábrát, úgy, hogy a részvételnél az elért pontszámot is tároljuk. Ez az új tulajdonság ekkor a kapcsolatot reprezentáló kapcsoló relációba fog bekerülni.

- n. fokú kapcsolat: mivel a kapcsolat a kapcsolókulcs-kulcs párokon alapszik, ezért ez a megközelítés a binér kapcsolatokon nyugszik. A magasabb fokú kapcsolatok leírására jó megközelítést ad, ha itt is bevezetünk egy kapcsoló relációt, melynek minden rekordelôfordulása egy konkrét kapcsolatot reprezentál. Ezen új reláció kulcsának a kapcsolatot kell azonosítania, s erre a kapcsolódó egyedelôfordulások kulcsainak együttesét szokták használni. A kapcsoló reláció kulcsa tehát magában foglalja az n darab kapcsolókulcsot is. Ez a megoldás lehetôvé teszi, hogy a kapcsoló relációba mezôként bevegyük azokat a tulajdonságokat is, melyek magát a kapcsolatot jellemzik, s nem csak a kapcsolódó egyedeket.

- totális kapcsolat: a kapcsolat totális voltának letárolása viszonylag egyszerûbb akkor, ha minden egyedelôfordulás csak egy kapcsolatelôfordulásban szerepel, tehát amikor az egyedhez tartozó reláció tartalmazza a kapcsolatra vonatkozó kapcsolókulcsot. Ekkor a kapcsolat totális jellege azt mondja ki, hogy egyetlen egy elôfordulásban sem maradhat a kapcsolókulcs értéke NULL. Ez a megkötés azonban elôírható a megfelelô integritási feltétel kiadásával. Ha azonban azon egyed kapcsolata totális, mely több másik egyed-elôfordulással is kapcsolatban áll, akkor a feltétel úgy szólna, hogy az adott reláció minden kulcsértékének elô kell fordulnia a másik relációban szereplô kapcsolókulcs értékek között. Ez viszont már egy összetettebb integritási feltétel, melyet csak bonyolultabb úton valósíthatunk meg, pl. triggerek segítségével. Még így is olyan problémákkal találkozhatunk, hogy miként kezeljük le azt az esetet, amikor mindkét irányban totális a kapcsolat, s ekkor milyen lehet a rekordok felviteli sorrendje. Ha ugyanis elôírjuk, hogy csak akkor vihetnék fel egy új rekordot, ha létezik kapcsolódó rekordja, akkor csak egyidejûleg vihetnénk fel a kapcsolódó rekordokat, amit már nehezebb lenne megoldani.
- specializáció, kategória: az EE/R modellbõl származó két fogalom valójában igen távol áll az alap relációs modelltõl. Hiszen ezek a fogalmak is kapcsolatokat írnak le, de nem egyedelôfordulások közötti kapcsolatot, hanem típusok közötti kapcsolatot ábrázolnak. Ezért a kulcs-kapcsolókulcs szerkezet nem igazán illik erre a kapcsolatra, hiszen az kizárólag a rekordelôfordulások közötti kapcsolatok leírására szolgál. Mivel a relációs modellben nincs megfelelô eszköz a típusok közötti kapcsolatok tárolására, ezért csak egy közelítést alkalmazhatunk a specializáció, kategória jelzésére a kulcs-kapcsolókulcs felhasználásával. Egyik lehetséges módszer, hogy egy leszármaztatott egyedet két relációba szétbontva tárolunk. Ekkor külön relációba kerül az általános rész és külön relációba a speciáis rész. A kér rész közötti kapcsolatot pedig egy kapcsoló kulcs segítségével valósítjuk meg. A specializált, leszármaztatott típushoz tehát egy olyan relációt hozunk létre, mely csak a speciális, egyedi tulajdonságok tárolására szolgáló mezõket tartalmazza, illetve emellett tartalmaz egy kapcsoló kulcsot a szülô relációhoz fûzôdô kapcsolat jelzésére is. Ekkor a specializált egyed összes tulajdonságának kiíratására több relációból kell a mezõket összegyüjteni.

A példában a teherautó reláció csak a speciális tulajdonságokat tartalamazzza a kapcsoló kulcs és elsõdleges kulcs szerepet is szerepet játszó rendszám mezõ mellett. A teherautó általános adatai az autó relációban kerülnek letárolásra. Így például a teherautó motorjának adatait az autó tábla megfelelõ rekordjából lehet kiolvasni.
kérdések:
- mennyi attributumot tartalmaz a legkisebb séma
- mennyi különbözõ relációséma képezhetõ az U = {nev, kor, ember} univerzumból?
- mennyi különbözõ relációséma képezhetõ egy n elemû U univerzumból?
- mennyi különbözõ reláció képezhetõ az R = {kor, nev} sémához,